




1. Balade dans le métro parisien▲
Les règles générales des « Défis C & C++ » sont décrites à cet endroit. Certaines de ces règles sont modifiées par le présent document.
Le défi de ce mois consiste à rechercher le plus cour chemin pour aller d'un point à un autre en utilisant le métro parisien.
Ce document présente :
- le rappel du fonctionnement du métro parisien ;
- la description de ce que doit faire le programme pour répondre au besoin de ce défi ;
- l'organisation mise en place autour de ce défi.
Un post est ouvert sur le forum à cet endroit permettant de discuter autour de ce défi. Les éventuelles questions et remarques doivent être posées à la suite dans ce post, les réponses seront apportées de manière publique toujours dans ce post.
Balade : Nom féminin (de ballade). Familier : Promenade
Ballade : Nom féminin (provenant de ballada, danse). I, Littérature 1, Poême à forme fixe composé généralement de trois strophes suivies d'un envoi d'une demi-strophe. 2, Poême narratif en strophes inspiré d'une légende ou d'une tradition historique. II, Musique 1, Chanson de danse. 2, Pièce vocale ou instrumentale inspirée par une ballade littéraire ou qui en reflète l'atmosphère. (Ballade pour un piano)
Source : Petit Larousse en couleurs édition 1990, donc non, je n'ai pas fait de faute dans le mot balade du titre du défi
2. Fonctionnement du métro parisien▲
Le plan général du métro parisien suivant servira de référence pour ce défi :
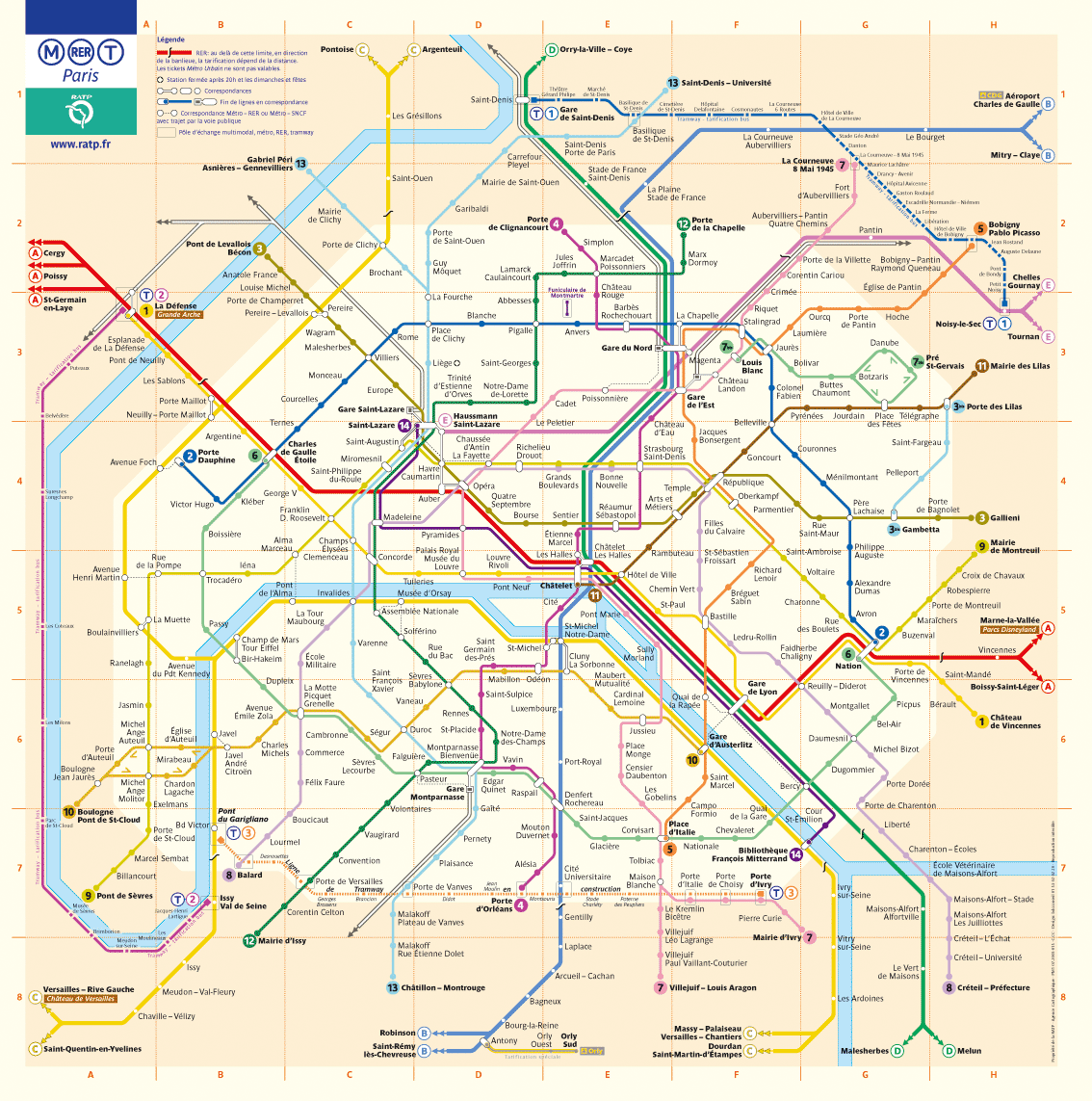
Il est composé de :
- 5 lignes de RER (la ligne A en rouge, la ligne B en bleu, la ligne C en jaune et la ligne D en vert, la ligne E en rose) ;
- 3 lignes de tramway (la ligne T1 en bleu, la ligne T2 en violet et la ligne T3 en orange) ;
- 1 ligne Orlyval (en jaune) ;
- de lignes SNCF au départ de la gare du Nord, la gare de l'Est, la gare Montparnasse, la gare Saint-Lazare ;
- 16 lignes de métro numérotées de ligne 1 à ligne 14 et les lignes 3bis et 7bis.
En général, pour indiquer son chemin à un touriste, les indications à donner sont de cette forme :
- prendre la ligne <nom de la ligne> direction <nom du terminus> et descendre à la station <nom de la station>
- puis
- prendre la ligne <nom de la ligne> direction <nom du terminus> et descendre à la station <nom de la station>
- etc.
Les quelques libertés et simplifications prises pour ce défi (que les puristes et autres amoureux du métro parisien m'excusent) sont :
- la ligne Orlyval n'est pas utilisée de même que les lignes SNCF au départ des grandes gares parisiennes ;
- les 5 lignes de RER ont été très largement simplifiées. Seules les stations intra-muros sont prises en compte ;
- certaines lignes de métro ont été modifiées et simplifiées afin de supprimer les petites particularités locales. Ainsi par exemple sur la ligne 13, le double terminus Gabriel Péri/Asnières-Gennevilliers et Saint-Denis-Université ont été supprimés pour ne laisser qu'un seul terminus Saint-Denis-Université. Ou encore sur la ligne 10, la boucle du côté de Boulogne Pont de Saint-Cloud a été supprimée ;
- les correspondances « piétonnes » (comme celle entre Pereire sur la ligne 3 et Pereire-Levallois sur le RER C) entre stations sont ignorées.
3. Spécification du programme▲
3-1. Fonctionnement du programme▲
Le fonctionnement attendu du programme de ce défi est le suivant :
- il doit utiliser la liste des lignes et des stations définies dans le paragraphe suivant (issue de la carte présentée dans le paragraphe précédent) ;
- les correspondances entre les différentes lignes doivent être détectées par la concordance des noms des stations sur les différentes lignes. Ainsi par exemple, sur la ligne 12 on trouve la station « Pigalle ». La station « Pigalle » se trouve aussi sur la ligne 2. La station « Pigalle » est donc une station de correspondance entre la ligne 2 et la ligne 12 ;
- il doit permettre de saisir le nom d'un point de départ quelconque (sur la carte du métro tout de même) et le nom d'un point d'arrivée quelconque (toujours sur la carte du métro) ;
- il y a une petite contrainte supplémentaire, lors de la saisie des noms des stations des points de départ et d'arrivée. Le programme doit être insensible aux différences majuscules/minuscules, aux accents et autres signes de ponctuation. C'est-à-dire que si l'utilisateur saisit « champs elysees, le programme doit comprendre qu'il parle en fait de la station »Champs-Elysées« . Par contre »Châtelet« est différent de »Châtelet-Les Halles" ;
- il programme doit rechercher le parcours le plus court possible en temps entre le point de départ et le point d'arrivée. Le temps de transport entre deux stations de même que le temps de changement de correspondance est arbitrairement fixé à une valeur constante. Ces 2 durées (temps entre deux stations et durée d'une correspondance) sont fixées par paramètre lors du lancement du programme (voir les options -c et -d décrites dans le paragraphe suivant). De plus, il n'y a pas de notion de lignes plus rapides que d'autres ou de stations plus éloignées que d'autres ;
- il doit afficher les indications permettant de se rendre du point de départ au point d'arrivée. Les noms des stations doivent reprendre l'orthographe issue du fichier décrivant la liste des lignes et des stations ;
- il doit afficher le temps total nécessaire au déplacement (temps de transport et temps de correspondance compris).
3-2. Paramètres du programme▲
Le programme doit accepter les paramètres suivants :
- « -h ». Cette option affiche l'aide en ligne du programme. À l'issue, le programme doit s'arrêter (même s'il y a d'autres options) ;
- « -v ». Cette option affiche le copyright du programme. À l'issue, le programme doit s'arrêter (même s'il y a d'autres options) ;
- « -f <fichier> ». Cette option permet d'indiquer au programme le nom du fichier décrivant les différentes lignes du métro ainsi que les stations qui les desservent ;
- « -d <délai> ». Cette option permet d'indiquer le temps moyen en secondes entre deux stations sur une même ligne. À titre indicatif, cette valeur pourrait être de 3 minutes (soient 180 secondes). Si cette option n'est pas spécifiée, sa valeur doit être demandée de manière interactive par le programme et saisie par l'utilisateur ;
- « -c <délai> ». Cette option permet d'indiquer le temps moyen en secondes d'une correspondance entre 2 lignes du métro. À titre indicatif, cette valeur pourrait être de 10 minutes (soient 600 secondes). Si cette option n'est pas spécifiée, sa valeur doit être demandée de manière interactive par le programme et saisie par l'utilisateur ;
- « -x <station de départ> ». Cette option permet d'indiquer le nom du point de départ. Si cette option n'est pas spécifiée, sa valeur doit être demandée de manière interactive par le programme et saisie par l'utilisateur ;
- « -y <station d'arrivée> ». Cette option permet d'indiquer le nom du point d'arrivée. Si cette option n'est pas spécifiée, sa valeur doit être demandée de manière interactive par le programme et saisie par l'utilisateur ;
- « -i <station intermédiaire> ». Cette option permet d'indiquer le nom d'une station intermédiaire. Il est alors obligatoire lors du transport du point de départ au point d'arrivée de passer par ce point intermédiaire. Cette option est facultative et peut être spécifiée plusieurs fois (il y aura alors plusieurs stations intermédiaires obligatoires) ;
- « -o ». Cette option permet d'activer ou non l'optimisation dans le cas des stations intermédiaires. Si cette option n'est pas présente, le passage aux stations intermédiaires doit impérativement respecter l'ordre des stations intermédiaires spécifié par l'utilisateur. Si cette option est positionnée, le programme est alors libre de modifier l'ordre de passage aux stations intermédiaires indiqué par l'utilisateur pour rechercher un temps de transport optimal.
L'ordre d'introduction des paramètres ne doit avoir aucune importance pour le fonctionnement du programme.
3-3. Format du fichier de description des lignes du métro parisien▲
Le format utilisé pour décrire les différentes lignes du métro parisien utilisé est le suivant :
- c'est un fichier au format Unicode ou UTF-8 ;
- les lignes du fichier vides doivent être ignorées ;
- les espaces ou tabulations en début et fin de ligne du fichier doivent être ignorés ;
- le nom de la ligne de métro est donné entre le caractère crochet ouvrant '[' et le caractère crochet fermant ']' ;
- les différentes stations qui composent une ligne de métro sont définies à raison d'une station par ligne du fichier entre deux noms de ligne de métro (ou un nom de ligne de métro et la fin du fichier).
[Nom de la ligne]
station 1
station 2
[Nom de la ligne]
station 1
station 2
...Ce fichier au format Unicode peut être téléchargé directement à cetteURL. C'est ce fichier sans aucune modification qui doit impérativement être utilisé par les participants à ce défi.
Le même fichier au format UTF-8 peut être téléchargé directement à cetteURL. C'est ce fichier sans aucune modification qui doit impérativement être utilisé par les participants à ce défi.
Les participants au défi peuvent utiliser indifféremment le fichier Unicode ou le fichier UTF-8. Toutefois, ils doivent clairement indiquer dans le fichier README accompagnant le projet quel format de fichier ils supportent. Il n'y a aucun bonus ni aucune pénalité à utiliser tel format plutôt que tel autre.
Les quelques modifications et simplifications apportées aux lignes du métro sont :
- Ligne 7 : Suppression du double terminus Le Kremlin-Bicêtre, Villejuif-Léo Lagrange, Villejuif-Paul Vaillant-Couturier, Villejuif-Louis Aragon ;
- Ligne 7bis : Suppression de la station Danube pour supprimer boucle ;
- Ligne 10 : Suppression des stations Michel-Ange-Molitor, Chardon-Lagache, Mirabeau pour supprimer la boucle ;
- Ligne 13 : Suppression du double terminus Asnières-Gennevilliers ;
- Lignes RER : suppression des stations se situant hors Paris intra-muros.
Il est possible que certaines erreurs d'orthographe se soient glissées dans la liste des stations fournie ci-dessus. Ceci ne devrait pas avoir d'impact sur le résultat obtenu, tout au plus une correspondance entre deux lignes ne serait pas détectée et le chemin obtenu ne correspondrait pas au chemin réel. Si vous détectez de telles erreurs, n'hésitez pas à m'envoyer un Message Privé afin que je rectifie cette liste.
3-4. Contraintes supplémentaires▲
Les contraintes suivantes doivent être respectées :
- le programme doit être écrit en C ou en C++ ;
- le programme doit être écrit pour les environnements Microsoft ou Linux ;
- l'environnement de développement utilisé pour écrire le programme est libre ;
- le programme doit fonctionner en mode « console » uniquement ;
- l'usage des librairies externes s'il n'est pas interdit doit être très limité. Le challenger ne doit pas perdre de vue que le programme doit pouvoir s'exécuter dans un environnement qui n'est pas forcément un environnement de développement. Les seules librairies qui ne posent pas de problèmes du fait de leur universalité sont boost et la STL pour le langage C++ et glib pour le langage C ;
- le programme doit être livré avec une documentation décrivant le fonctionnement interne du programme, les algorithmes utilisés, les techniques de développement utilisées et toutes les autres choses qui pourraient être intéressantes ;
- le programme doit être livré avec une description sur la manière de recompiler entièrement le programme.
4. Déroulement du défi▲
4-1. Durée du défi▲
La durée de ce défi est de 5 semaines à compter de son ouverture publique. Cette durée pourra éventuellement être modifiée si des conditions particulières l'exigent.
La date de début du défi est fixée au dimanche 9 mai 2009 et la date de fin de soumissions des projets est fixée au dimanche 14 juin 2009 à minuit (c'est la date et heure de dépôt du fichier qui fera foi).
4-2. Critères d'évaluation des programmes▲
Chacun des projets proposés est noté sur 20 et les critères de notation retenus pour ce défi sont les suivants :
|
Critère d'évaluation |
Note |
|---|---|
|
Fonctionnement du programme |
8 |
|
Capacité du programme à résister à un mauvais paramètre ou à un mauvais format de fichier de description des lignes de métro |
1 |
|
Capacité du programme à résister aux erreurs de saisie de l'utilisateur |
1 |
|
Calcul de l'itinéraire sans étape intermédiaire. C'est la pertinence de l'itinéraire qui est notée en premier |
2 |
|
Calcul de l'itinéraire avec gestion des étapes intermédiaires. C'est la pertinence de l'itinéraire qui est notée en premier |
2 |
|
Affichage de l'itinéraire. C'est uniquement l'aspect « esthétique » de la présentation qui est noté |
2 |
|
Documentation |
3 |
|
Complétude par rapport à ce qui est demandé |
1 |
|
Innovation dans les idées implémentées dans le code |
2 |
|
Analyse du code |
7 |
|
Organisation des fichiers |
1 |
|
Découpage en modules/classes |
1 |
|
Lisibilité du code |
2 |
|
Simplicité du code |
3 |
|
Recompilation |
2 |
|
Complétude de la procédure et recompilation du programme |
1 |
|
Non-utilisation de librairies externes. L'usage de librairie externe sera détecté lors de la phase de link et c'est le bon sens collégial du jury qui statuera. |
1 |
|
Autre |
|
|
Bonus C vs C++. Cet extra bonus est fait pour redonner un petit avantage aux programmes écrits en C compte tenu du travail et de l'effort supplémentaire nécessaire pour écrire en C |
2 |
4-3. Composition du jury▲
5. Analyse des résultats▲
5-1. Commandes de test▲
Ce paragraphe présente les commandes qui ont été passées aux différents programmes ainsi que les résultats attendus. Les résultats attendus sont « à peu près » le comportement du programme dans ce cas de figure.
|
Commande |
Résultat attendu |
|---|---|
|
Programme |
Doit afficher l'aide en ligne ou la version ou quelque chose donnant des informations pour savoir comment lancer le programme |
|
Programme -h |
Doit afficher l'aide en ligne. Cette aide en ligne doit être intelligible pour être utile. |
|
Programme -v |
Doit afficher le copyright (et la version) du programme |
|
Programme -f <fichier inexistant> |
Un message d'erreur doit être affiché |
|
Programme -f <fichier> -a |
Erreur avec un message d'erreur « paramètre -a non pris en compte » |
|
Programme -f <fichier> + erreurs de saisie de l'utilisateur |
Doit demander les deux délais, les stations de départ et d'arrivée et doit gérer correctement les erreurs de saisie de l'utilisateur |
|
Programme -f <fichier> -d 180 -c 600 -x concorde -y solferin |
station « solferin » inexistante |
|
Programme -f <fichier> -d 180 -c 600 -x assemble nationale -y solferino |
station « assemble nationale » inexistante ou paramètre « nationale » non géré |
|
Programme -f <fichier> -d 180 -c 600 -x concorde -y solferino |
6 minutes plus les indications |
|
Programme -f <fichier> -d 180 -c 600 -x « assemblee nationale » -y solferino |
3 minutes plus les indications |
|
Programme -f <fichier> -d 180 -c 600 -x tuileries -y rennes |
28 minutes plus les indications (1 changement) |
|
Programme -f <fichier> -d 180 -c 600 -x simplon -y wagram |
53 minutes plus les indications (2 changements) |
|
Programme -f <fichier> -d 180 -c 600 -x simplon -y wagram -i jourdain -i goncourt |
2 heures 8 minutes plus les indications |
|
Programme -f <fichier> -d 180 -c 600 -x simplon -y wagram -i goncourt -i « chateau rouge » |
2 heures 29 minutes plus les indications |
|
Programme -f <fichier> -d 180 -c 600 -x simplon -y wagram -i goncourt -i « chateau rouge » -o |
1 heure 53 minutes plus les indications |
5-2. Participants▲
Les personnes ayant participé jusqu'au bout à ce défi sont par ordre alphabétique :
Nous les remercions pour de leur participation à ce défi ainsi que tous les autres participants qui ne sont pas allées jusqu'au bout de la démarche, mais qui ont tenté de participer.
5-3. Commentaires sur les solutions proposées▲
Pour chacune des solutions proposées sont présentées la vision et l'analyse faite par le challenger ainsi que la notation du projet faite par le jury C & C++ de ce défi. Un récapitulatif de la notation des différents projets est présenté dans le paragraphe 6.4
5-3-1. Climoo (corrigé par Davidbrcz)▲
La solution proposée par Climoo peut être téléchargée ici (format zip).
Il s'agit d'un projet écrit en C, utilisant le compilateur gcc pour un environnement Windows XP ou Ubuntu.
5-3-1-1. Analyse par le challenger▲
Le programme principal se décompose en plusieurs parties :
- évaluer la requête formulée par l'utilisateur (station de départ et d'arrivée, temps moyen…) ;
- effectuer la lecture du fichier des stations ;
- chercher un itinéraire répondant à la requête formulée ;
- afficher le résultat.
Choix de modélisation : il s'agit ici de représenter les liens qui existent entre des stations de métro d'une ville, afin de rechercher des itinéraires entre elles. Une représentation simple est celle sous forme de graphe. Chaque sommet est une station, chaque « portion » de ligne entre deux stations forme un arc. Il existe plusieurs moyens efficaces de représenter un graphe, ici on a choisi la modélisation sous forme de listes d'adjacence (pour chaque sommet du graphe, on stocke dans une liste chaînée, l'ensemble de ses successeurs). Les valuations des arcs, c'est-à-dire les distances entre les stations, ont toutes été supposées égales. En réalité, pour passer d'une station à une autre, il y a un cout qui varie selon le fait qu'il soit nécessaire de changer ou non de ligne. Pour passer d'une station à l'autre, on stockera simplement via quelle ligne cela peut se faire (dans les maillons des listes chaînées).
Algorithmes utilisés
- Pour calculer le plus court chemin d'une station à une autre, l'algorithme de Dijkstra a été utilisé, car c'est un algorithme simple et efficace, qui permet de connaître (en un temps polynomial), tous les plus courts chemins à partir d'une station, ainsi que le temps nécessaire mis pour y parvenir. Grâce à cet algorithme, on peut déjà répondre à une requête simple de l'utilisateur, à savoir quel est le plus court chemin d'une station à une autre du métro.
- Pour calculer un itinéraire multiple, mais dont l'ordre des étapes est imposé, cela revient a calculer plusieurs itinéraires simples, et de les mettre chacun bout à bout, afin de créer l'itinéraire final.
- Dans le cas ou l'ordre des étapes n'est pas défini, on se trouve alors face à un problème beaucoup plus complexe, qui ne peut être résolu en un temps normal, pour un nombre suffisamment important de stations intermédiaires (en effet, le nombre de chemins à explorer est de l'ordre de la factorielle du nombre de stations intermédiaires).
Deux approches ont été utilisées pour proposer une solution.
La première consiste à construire un arbre, pour lequel chaque nœud correspond à une station. La racine est la station de départ, et chacun de ses successeurs est les stations vers lesquelles il est possible de se rendre. Puis, à partir de chacune de ses stations, on stocke de nouveau les stations vers lesquelles il est possible de se rendre (moins la première), etc. Il va de soi que seul le chemin le plus court est utilisé (calculé à l'aide de Dijkstra). On progresse ainsi dans l'arbre, jusqu'à parvenir à la station d'arrivée (nécessairement la dernière du trajet). À ce moment, on recherche alors la feuille de l'arbre qui a la distance la plus courte ; c'est celle qui contient l'itinéraire optimal. On peut alors, en remontant à partir de cette feuille jusque la racine, déterminer cet itinéraire. Cette méthode, complète, assure de trouver le meilleur itinéraire. Cependant, comme expliqué plus haut, il n'est pas possible dans la pratique de l'utiliser, si le nombre de stations intermédiaires est trop élevé. Expérimentalement et avec les performances de la machine sur laquelle ont été faits les tests, ce seuil a été fixé à 8.
Au-delà de ce seuil, on applique donc une autre méthode, moins coûteuse, mais qui ne garantit pas la totale optimalité du trajet. On va en fait choisir l'ordre des stations en commençant par celle qui se trouve la plus proche de celle de départ, puis par celle qui est de nouveau la plus proche, jusqu'à parvenir à la station d'arrivée. Dans la pratique, cette heuristique de choix n'est pas des plus mauvaises, et l'itinéraire trouvé peut être considéré satisfaisant, pour un simple parisien désireux de visiter un grand nombre de stations de métro…
5-3-1-2. Notation▲
|
Critère |
Commentaire |
Note |
|
|---|---|---|---|
|
Fonctionnement du programme |
6/8 |
||
|
Capacité du programme à résister à un mauvais paramètre ou à un mauvais format de fichier de description des lignes de métro |
OK |
1/1 |
|
|
Capacité du programme à résister aux erreurs de saisie de l'utilisateur |
OK |
1/1 |
|
|
Calcul de l'itinéraire sans étape intermédiaire. C'est la pertinence de l'itinéraire qui est notée en premier |
OK |
2/2 |
|
|
Calcul de l'itinéraire avec gestion des étapes intermédiaires. C'est la pertinence de l'itinéraire qui est notée en premier |
Le programme ne donne pas les résultats attendus. Pour le 1er exemple avec station intermédiaire, il propose un itinéraire en 2H31 (le meilleur est en 2H08), pour le 2e, il trouve 2H32 (le meilleur est en 2H29), pour le 3e, il trouve 2H06 alors que le meilleur est en 1H53. |
0/2 |
|
|
Affichage de l'itinéraire. C'est uniquement l'aspect « esthétique » de la présentation qui est noté |
Clair, net et précis |
2/2 |
|
|
Documentation |
2,5/3 |
||
|
Complétude par rapport à ce qui est demandé |
Lorsque le programme est lancé sans paramètres, il n'affiche pas l'aide, mais demande de rentrer le fichier de description du réseau. |
0,5/1 |
|
|
Innovation dans les idées implémentées dans le code |
Dijkistra, bonnes heuristiques, RAS |
2/2 |
|
|
Analyse du code |
6/7 |
||
|
Organisation des fichiers |
Rien à dire |
1/1 |
|
|
Découpage en modules/classes |
Tout y est |
1/1 |
|
|
Lisibilité du code |
Le code est très compact dans certains fichiers, pas (ou peu) d'espace dans le corps des fonctions. L'identification des blocs logiques est plus difficile. Pas énormément de commentaires dans les fonctions, donne l'impression de manipuler des black box. Par contre, il faudrait éviter de laisser du code mort. Ce n'est pas grand-chose, mais ça fait toujours mauvaise impression. |
1/2 |
|
|
Simplicité du code |
Bonne analyse et bon découpage. Les fonctions sont juste à la bonne longueur. |
3/3 |
|
|
Recompilation |
2/2 |
||
|
Complétude de la procédure et recompilation du programme |
RAS |
1/1 |
|
|
Non-utilisation de librairies externes. L'usage de librairie externe sera détecté lors de la phase de link et c'est le bon sens collégial du jury qui statuera |
RAS |
1/1 |
|
|
Bonus/Malus |
|||
|
Bonus projet C |
2 |
||
|
Total |
18,5/20 |
5-3-2. jfouche (corrigé par Davidbrcz)▲
La solution proposée par jfouche peut être téléchargée ici (format zip).
Il s'agit d'un projet écrit en C++, utilisant le compilateur gcc et MinGW pour un environnement Windows ou Linux.
5-3-2-1. Analyse par le challenger▲
Algorithme : L'idée est de se baser sur l'utilisation des graphes. Il faut donc modéliser le plan du métro sous forme de graphe. Le graphe utilisé sera non orienté, car nous pouvons parcourir les lignes dans un sens comme dans l'autre.
Modélisation d'une ligne : Soit S1…Sn les différentes stations d'une ligne de métro, et d le delai entre 2 stations d'une même ligne. La modélisation choisie est la suivante :

Modélisation d'une correspondance. Une correspondance est l'endroit ou 2 lignes se rejoignent. Soit c le délai pour parcourir la correspondance. La modélisation choisie est la suivante :
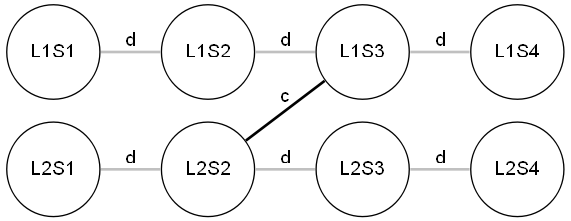
ou la 2de station de la ligne 2 correspond avec le 3e station de la ligne 1 (les 2 stations ont le même nom).
Modélisation du départ et de l'arrivée : Pour implémenter le départ et l'arrivée, je crée 2 stations virtuelles (D et A). Je connecte ces stations au graphe via l'ensemble de leurs correspondances.
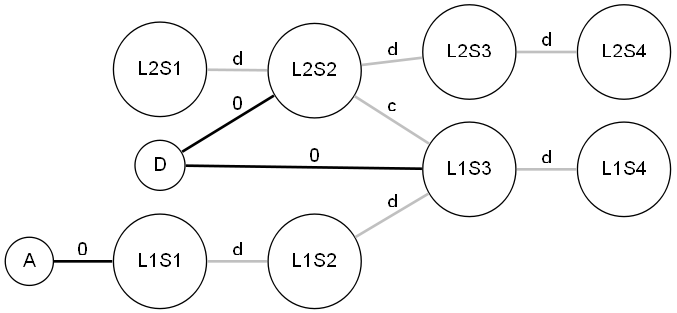
Modélisation d'une étape : Pour implémenter une étape, je crée une station virtuelle (E sur l'image), connectée au graphe représentant le plan du métro.
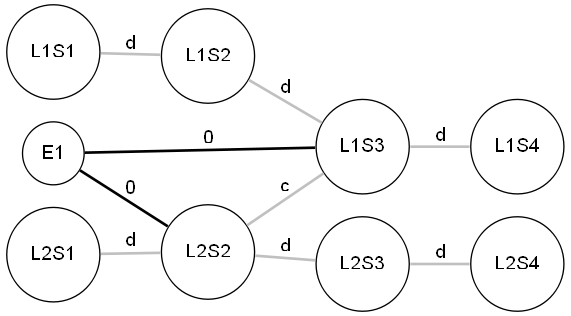
Pour la suite, j'appellerai G le graph représentant un plan de métro sans étape, et En l'étape n. Tous les graph G sont identiques.Ce qui donne le graphe simplifié suivant pour une étape :
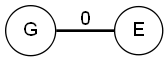
Modélisation du trajet non optimisé : Dans le cas du trajet non optimisé, on doit parcourir l'ensemble des étapes dans l'ordre. Le graphe devient le suivant.

Modélisation du trajet optimisé : Dans le cas du trajet optimisé, on doit parcourir l'ensemble des étapes dans un ordre quelconque afin de trouver le chemin le plus court. Le graphe devient le suivant pour 3 étapes.

5-3-2-2. Notation▲
|
Critère |
Commentaire |
Note |
|
|---|---|---|---|
|
Fonctionnement du programme |
6,5/8 |
||
|
Capacité du programme à résister à un mauvais paramètre ou à un mauvais format de fichier de description des lignes de métro |
OK |
1/1 |
|
|
Capacité du programme à résister aux erreurs de saisie de l'utilisateur |
Le programme se crash si on donne des valeurs négatives pour -c et -d |
0,5/1 |
|
|
Calcul de l'itinéraire sans étape intermédiaire. C'est la pertinence de l'itinéraire qui est notée en premier |
OK |
2/2 |
|
|
Calcul de l'itinéraire avec gestion des étapes intermédiaires. C'est la pertinence de l'itinéraire qui est notée en premier |
OK, les itinéraires optimaux sont trouvés |
2/2 |
|
|
Affichage de l'itinéraire. C'est uniquement l'aspect « esthétique » de la présentation qui est noté |
Affichage un peu brut. |
1/2 |
|
|
Documentation |
2,5/3 |
||
|
Complétude par rapport à ce qui est demandé |
-c et -d devaient pouvoir être saisis « à la volée ». |
0,5/1 |
|
|
Innovation dans les idées implémentées dans le code |
Utilisation de boost::graph, clair net et précis |
2/2 |
|
|
Analyse du code |
5/7 |
||
|
Organisation des fichiers |
1 fichier par unité sémantique |
1/1 |
|
|
Découpage en modules/classes |
Seulement 3 classes utiles (Plan, Graph, StationData), c'est peu, car le projet est quand même relativement conséquent. D'ailleurs, ça se voit, car Plan est une super classe (dans le sens où elle fait tout). Il aurait sans doute fallu continuer à décomposer Plan selon ses différents rôles. |
0,5/1 |
|
|
Lisibilité du code |
Indentation: Ok, Nom: Ok, Aérer le code un peu plus (découper blocs commentaires/instructions). |
1,5/2 |
|
|
Simplicité du code |
La longueur des méthodes dans plan est un peu trop longue (c'est lié a un découpage insuffisant en classe). Les options en brut dans main, il aurait été bien de leur consacrer une classe. Je n'ai pas compris l'intérêt de StationData. |
2/3 |
|
|
Recompilation |
1,5/2 |
||
|
Complétude de la procédure et recompilation du programme |
Obligation de modifier le makefile pour enlever les chemins en dur, sinon RAS. |
0,5/1 |
|
|
Non-utilisation de librairies externes. L'usage de librairie externe sera détecté lors de la phase de link et c'est le bon sens collégial du jury qui statuera |
OK |
1/1 |
|
|
Bonus/Malus |
|||
|
Bonus projet C |
|||
|
Total |
15,5/20 |
5-3-3. Nogane (corrigé par ram-0000)▲
La solution proposée par Nogane peut être téléchargée ici (format zip).
Il s'agit d'un projet écrit en C++, utilisant l'environnement MinGW 4.3 / g++ 4.3 sous CodeBlocks et fonctionnant sous Windows XP et Ubuntu 9.04.
5-3-3-1. Analyse par le challenger▲
Comment l'Unicode a-t-il été géré ?
- Pour la lecture du fichier. Pour lire le fichier Unicode j'ai créé un codecvt_facet : utf16_codecvt_facet qui se charge de la conversion utf16 -> wchar_t. L'UTF-8 est géré par la facette utf8_codecvt_facet de boost.
- Pour la ligne de commande. Pour windows, la difficulté est de convertir son sharset OEM en Unicode. La seule solution simple que j'ai trouvée, c'est d'utiliser son CommandLineToArgvW. Ce n'est pas standard, mais comme ce n'est utile que sous windows, ça devrait aller. Pour les systèmes en UTF_8, c'est boost::program_options qui s'en occupe.
- Pour wcin, et wcout. Pour windows et Linux, c'est setlocale qui a résolu mon problème. Hélas il semble que les chaînes des locales ne soient pas standard. Donc je ne suis pas sur de la portabilité.
- Conclusion. La lecture d'un fichier Unicode ou UTF-8 peut se faire avec un effort raisonnable : en créant un codecvt_facet. Mais récupérer les entrées utilisateur s'avère être un véritable casse-tête. On n'a apparemment pas de moyen de savoir quels sont l'encodage et le charset en entrée. De plus, ils peuvent être différents sous un même système. Par exemple avec CodeBlock, si je lance mon projet de la console, je suis en OEM, si je le lance d'un .bat je suis en ANSI, et si je le lance de CodeBlocks la ligne de commande est en UTF-8. De plus les chaînes à passer aux locales ne sont pas standardisées, et le sujet ne semble pas très documenté (codecvt pour changer l'encodage, mais pour le charset ??) alors je serais curieux de connaître la solution simple, claire, portable, sans abus de ifdef, pour pouvoir lire une ligne de commande avec des caractères accentués.
Comment les comparaisons de chaînes ont été gérées ? En créant un collate (héritant de std::collate), nommé DVPCollate. Il s'occupe de faire les comparaisons ou les conversions en chaîne sans accent ni majuscule.
Comment trouver le chemin le plus court entre deux stations ?
- Idée de départ. Au premier abord, on aurait tendance à se dire: déplaçons-nous de station en station, à partir de la première. Testons toutes les possibilités de chemin et gardons la meilleure. Ça marche à condition de ne pas boucler. Pour ça il faut s'interdire de reprendre un tronçon déjà utilisé, dans le même sens.
- Principale amélioration. Ça marche, mais une première grosse optimisation me vient à l'esprit : quand on parcourt une ligne, pourquoi perdre du temps à faire toutes les stations, alors qu'on sait qu'on va aller : ou à une intersection ou à la station finale (à condition d'être sur une ligne qui y va). J'appellerai croisement une station desservie par plusieurs lignes. Dans la première méthode, on avait besoin d'un tableau associatif qui pour une station nous donne toute les stations contiguës et la ligne qui y va. En revanche, pour cette deuxième méthode il faut avoir deux tableaux associatifs : un qui pour une station nous donne toutes les lignes accessibles ou un autre qui pour une ligne nous donne tous les croisements accessibles. (Remarquez qu'on ne s'intéresse pas aux autres stations)
- Optimisations classiques. Les optimisations qui suivent sont assez classiques. Il s'agit de couper la recherche le plus tôt possible. C'est-à-dire de détecter le plus tôt possible qu'un chemin ne sera pas intéressant. La première méthode est la plus évidente : si la durée du chemin en cours de test est déjà plus longue que la meilleure durée déjà trouvée inutile de continuer. L'idée suivante est inspirée de l'algorithme de Dijkstra. L'idée de départ c'est que si on est déjà venu à une station en moins de temps, il est inutile de poursuivre ce chemin, alors qu'on sait qu'il lui existe une alternative plus courte. Cependant ce n'est pas si simple dans notre cas à cause temps perdu aux changements de ligne. En effet, si on est déjà venu à une station en moins de temps, ce n'était pas forcement par la même ligne. Donc la solution actuelle a encore une chance d'être meilleure, en évitant un changement de ligne. Mais cette idée est quand même utilisable, à condition de l'adapter. Puisqu’on peut connaître le meilleur temps fait pour une station, pour chaque ligne qui y mène.
- Comment trouver le meilleur chemin, avec des étapes (sans optimisation de l'ordre) ? Dans ce cas, aucune difficulté. Il suffit de demander les chemins de stations à stations, dans l'ordre demandé. Une toute petite optimisation aurait été possible, il s'agit de ne pas recalculer le même chemin si la même paire de stations apparaît deux fois. Je ne l'ai pas fait.
- Comment trouver le meilleur chemin, avec des étapes (avec optimisation de l'ordre) ? Pour se simplifier la vie, on va commencer pas une petite optimisation toute bête : Supprimer les doublons. En effet, si l'utilisateur se fiche de l'ordre des étapes, on peut supposer que le chemin le plus court pour aller trois fois à une même station… c'est d'y rester.
5-3-3-2. Notation▲
|
Critère |
Commentaire |
Note |
|
|---|---|---|---|
|
Fonctionnement du programme |
6,5/8 |
||
|
Capacité du programme à résister à un mauvais paramètre ou à un mauvais format de fichier de description des lignes de métro |
Les mauvais paramètres sont bien gérés, mais il n'y a pas de message d'erreur pour aider l'utilisateur à comprendre son erreur. Certains comportements sont bizarres (sans plus d'explication, il faudrait débugger). Par exemple, malgré que le paramètre -d soit donné, le programme demande tout de même la durée de changement ou encore il affiche deux fois de la ligne demandant le nom de la station de départ. |
0/1 |
|
|
Capacité du programme à résister aux erreurs de saisie de l'utilisateur |
Les erreurs de saisie sont bien gérées, mais il n'y a pas de message d'erreur pour aider l'utilisateur à comprendre ses erreurs. |
0,5/1 |
|
|
Calcul de l'itinéraire sans étape intermédiaire. C'est la pertinence de l'itinéraire qui est notée en premier |
OK |
2/2 |
|
|
Calcul de l'itinéraire avec gestion des étapes intermédiaires. C'est la pertinence de l'itinéraire qui est notée en premier |
OK |
2/2 |
|
|
Affichage de l'itinéraire. C'est uniquement l'aspect « esthétique » de la présentation qui est noté |
L'affichage est clair et sans ambiguïté |
2/2 |
|
|
Documentation |
2/3 |
||
|
Complétude par rapport à ce qui est demandé |
Une option supplémentaire existe (-t) et n'est pas expliquée. |
0,5/1 |
|
|
Innovation dans les idées implémentées dans le code |
Le support des fichiers utf-8 est prévu (mais n'a pas été testé). Projet C++ qui n'utilise pas boost::graph. L'algorithme utilisé est un algorithme brute force. Dans le cadre de ce défi, cela suffit, mais sur un réseau maillé plus important, les limites en termes de performances de ce type d'algorithme devraient se faire ressentir. |
1,5/2 |
|
|
Analyse du code |
6/7 |
||
|
Organisation des fichiers |
Un découpage en fichiers simple a comprendre, les différentes fonctionnalités semblent bien isolées. |
1/1 |
|
|
Découpage en modules/classes |
Clairement, le découpage en classes montre que les évolutions possibles ont déjà été prises en compte ou tout au moins anticipées. |
1/1 |
|
|
Lisibilité du code |
Très (trop) peu de commentaires toutefois, les fonctions sont courtes (quelques lignes) et leur rôle est assez facile à comprendre de par leur nom |
1/2 |
|
|
Simplicité du code |
Le code n'est pas simple à appréhender du fait du nombre de classes (une vingtaine) par contre, la documentation générée par doxygen dans le projet montre l'arborescence de classes utilisée. Sans cette documentation, la prise en main du projet risque d'être un peu ardue. |
3/3 |
|
|
Recompilation |
1,5/2 |
||
|
Complétude de la procédure et recompilation du programme |
Portage du projet en environnement Visual Studio 2005 sous Windows XP. En niveau 3, 5 warning (warning C4267: 'argument' : conversion de 'size_t' en 'const int', perte possible de données) |
0,5/1 |
|
|
Non-utilisation de librairies externes. L'usage de librairie externe sera détecté lors de la phase de link et c'est le bon sens collégial du jury qui statuera |
Utilisation de la librairie boost |
1/1 |
|
|
Bonus/Malus |
|||
|
Bonus projet C |
|||
|
Total |
16/20 |
5-4. Récapitulatif des notations▲
|
Climoo |
jfouche |
Nogane |
||
|---|---|---|---|---|
|
Fonctionnement du programme |
8 |
6 |
6,5 |
6,5 |
|
Capacité du programme à résister à un mauvais paramètre ou à un mauvais format de fichier de description des lignes de métro |
1 |
1 |
1 |
0 |
|
Capacité du programme à résister aux erreurs de saisie de l'utilisateur |
1 |
1 |
0,5 |
0,5 |
|
Calcul de l'itinéraire sans étape intermédiaire. C'est la pertinence de l'itinéraire qui est notée en premier |
2 |
2 |
2 |
2 |
|
Calcul de l'itinéraire avec gestion des étapes intermédiaires. C'est la pertinence de l'itinéraire qui est notée en premier |
2 |
0 |
2 |
2 |
|
Affichage de l'itinéraire. C'est uniquement l'aspect « esthétique » de la présentation qui est noté |
2 |
2 |
1 |
2 |
|
Documentation |
3 |
2,5 |
2,5 |
2 |
|
Complétude par rapport à ce qui est demandé |
1 |
0,5 |
0,5 |
0,5 |
|
Innovation dans les idées implémentées dans le code |
2 |
2 |
2 |
1,5 |
|
Analyse du code |
7 |
6 |
5 |
6 |
|
Organisation des fichiers |
1 |
1 |
1 |
1 |
|
Découpage en modules/classes |
1 |
1 |
0,5 |
1 |
|
Lisibilité du code |
2 |
1 |
1,5 |
1 |
|
Simplicité du code |
3 |
3 |
2 |
3 |
|
Recompilation |
2 |
2 |
1,5 |
1,5 |
|
Complétude de la procédure et recompilation du programme |
1 |
1 |
0,5 |
0,5 |
|
Non-utilisation de librairies externes |
1 |
1 |
1 |
1 |
|
Autre |
||||
|
Bonus C vs C++ |
2 |
0 |
0 |
|
|
Pénalité |
||||
|
Total |
18,5/20 |
15,5/20 |
16/20 |
5-5. Synthèse des notes▲
- Climoo a obtenu une note de 18,5/20.
- jfouche a obtenu une note de 15,5/20.
- Nogane a obtenu une note de 16/20.
Le gagnant de ce défi est donc Climoo et nous le félicitons tous.
Remarque : La notation du défi repose sur un tout. Même si Climoo a présenté un algorithme faillible (il ne trouve pas le meilleur itinéraire lorsqu'il y a des stations intermédiaires), les critères de notation de ce défi font qu'il est tout de même le gagnant. Il a été meilleur que les autres projets sur d'autres points ce qui lui a permis de rattraper ce handicap.
6. Conclusion▲
De manière globale, on retiendra dans ce défi :
- peu de participants à l'arrivée malgré l'engouement initial ;
- un défi qu'il a fallu simplifier en cours de route pour supprimer la gestion de l'Unicode (ou tout au moins laisser le choix aux développeurs) ;
- l'excellente qualité des projets soumis avec du code et de la documentation de facture professionnelle.
La page WWW du défi a été consultée 3292 fois (2935 consultations uniques) entre le 8 mai et 27 juin 2009. Le post du défi dans le forum a été consulté 4021 fois sur la même période.
Encore une fois, nous tenons à remercier tous les participants à ce défi et à féliciter notre grand gagnant Climoo qui se verra remettre rapidement son prix sous la forme d'un bon d'achat Amazon de 40 € offert par la rédaction de developpez.com.
Nous espérons vous retrouver nombreux pour un prochain défi.