

VIII. Autres éléments du langage C▲
Cette section regroupe un ensemble de notions ayant en commun que leur intérêt apparait surtout à l'occasion de l'écriture de gros programmes. Ce sont des éléments importants du langage mais, sauf quelques exceptions, on peut s'en passer aussi longtemps qu'on limite la pratique de C à des exercices de petite taille.
VIII-A. Le préprocesseur▲
Le préprocesseur transforme le texte source d'un programme avant que la compilation ne commence.
Généralement associées au processus de la compilation, ses actions semblent en faire partie, mais il faut sa- voir que le préprocesseur est un programme séparé, largement indépendant du compilateur. En particulier le préprocesseur ne connait pas la syntaxe du langage C. Les transformations qu'il effectue sur un programme sont simplement des ajouts, des suppressions et des remplacements de morceaux de texte nullement astreints à correspondre aux entités syntaxiques du langage.
Les directives destinées au préprocesseur comportent, dans l'ordre :
- un signe # (qui, en syntaxe originale, doit occuper la première position de la ligne)
- un mot-clé parmi include, define, if, ifdef, ifndef, else et endif qui identifie la directive. Nous passerons sous silence quelques autres directives mineures comme pragma, line ou error
- le corps de la directive, dont la structure dépend de la nature de celle-ci.
VIII-A-1. Inclusion de fichiers▲
La possibilité d'inclure des fichiers sources dans d'autres fichiers sources s'avère très utile, par exemple pour insérer dans chacun des fichiers séparés qui constituent un programme l'ensemble de leurs déclarations communes (types, structures, etc.). Ainsi ces définitions sont écrites dans un seul fichier, ce qui en facilite la maintenance.
Un cas particulier très important de ce partage des déclarations est celui des bibliothèques livrées avec le compilateur. Elles sont essentiellement composées de fonctions utilitaires déjà compilées dont seul le fichier objet est fourni. Pour que les appels de ces fonctions puissent être correctement compilés 61 dans des programmes qui les utilisent, un certain nombre de fichiers en-tête sont livrés avec les bibliothèques, comprenant
- principalement, les prototypes des fonctions qui forment la bibliothèque ou qui incarnent une fonctionnalité particulière (les entrées - sorties, la gestion des chaines de caractères, la bibliothèque mathématique, etc.) ;
- souvent, un ensemble de directives #define et de déclarations struct, union et typedef qui définissent les constantes et les types nécessaires pour utiliser la bibliothèque en question ;
- parfois, quelques directives #include concernant d'autres fichiers en-tête lorsque les éléments définis dans le fichier en-tête en question ne peuvent eux-mêmes être compris sans ces autres fichiers ;
- plus rarement, quelques déclarations de variables externes.
Cette directive possède deux formes :
#include "nom-de-fichier"C'est la forme générale. Le fichier spécifié est inséré à l'endroit ou la directive figure avant que la compilation ne commence ; ce doit être un fichier source écrit en C. La chaine de caractères "nom-de-fichier" doit être un nom complet et correct pour le système d'exploitation utilisé.
La deuxième forme est :
#include <nom-de-fichier>Ici, le nom est incomplet ; il ne mentionne pas le chemin d'accès au fichier, car il est convenu qu'il s'agit d'un fichier appartenant au système, faisant partie de la bibliothèque standard : le préprocesseur « sait » dans quels répertoires ces fichiers sont rangés. Ce sont des fichiers dont le nom se termine par .h (pour header, en-tête) et qui contiennent les déclarations nécessaires pour qu'un programme puisse utiliser correctement les fonctions de la bibliothèque standard.
Exemples (avec des noms de fichier en syntaxe UNIX) :
#include <stdio.h>
#include "/users/henri/projet_grandiose/gadgets.h"Attention. Il ne faut pas confondre inclusion de fichiers et compilation séparée. Les fichiers que l'on inclut au moyen de la directive #include contiennent du texte source C qui sera compilé chaque fois que l'inclusion sera faite (c'est pourquoi ces fichiers ne contiennent jamais de fonctions). Le service rendu par la directive #include est de permettre d'avoir un texte en un seul exemplaire, non de permettre de le compiler une seule fois.
61Notez bien qu'il ne s'agit pas de fournir les fonctions de la bibliothèque (cela est fait par l'apport du fichier objet au moment de l'édition de liens) mais uniquement de donner l'information requise pour que les appels de ces fonctions puissent être correctement traduits par le compilateur. Pour cette raison on ne trouve jamais dans les fichiers en-tête ni des variables non externes, ni le corps des fonctions.
VIII-A-2. Définition et appel des "macros"▲
Les macros sans argument 62 se définissent par la directive :
#define nom corpsLe nom de la macro est un identificateur. Le corps de la macro s'étend jusqu'à la fin de la ligne 63. Partout dans le texte ou le nom de la macro apparait en qualité d'identificateur (ce qui exclut les commentaires, les chaines de caractères et les occurrences ou le nom de la macro est collé à un autre identificateur), il sera remplacé par le corps de la macro, lequel est un texte quelconque n'ayant à obéir à aucune syntaxe. Par exemple, entre l'endroit ou figurent les deux directives suivantes :
#define NBLIGNES 15
#define NBCOLONNES (2 * NBLIGNES)et la fin du fichier où elles apparaissent, chaque occurrence de l'identificateur NBLIGNES sera remplacée par le texte 15 et chaque occurrence de l'identificateur NBCOLONNES par le texte (2 * 15). Au moins d'un point de vue logique, ces remplacements se feront avant que la compilation ne commence. Ainsi, à la place de
double matrice[NBLIGNES][NBCOLONNES];le compilateur trouvera
double matrice[15][(2 * 15)];(il remplacera immédiatement 2 * 15 par 30).
Attention. Voici une erreur que l'on peut faire :
#define NBLIGNES 15;
#define NBCOLONNES (2 * NBLIGNES);C'est une erreur difficile à déceler, car le compilateur ne signalera ici rien de particulier. Mais plus loin il donnera pour erronée une déclaration comme :
double matrice[NBLIGNES][NBCOLONNES];En effet, cette expression qui parait sans défaut aura été transformée par le préprocesseur en 64
double matrice[15;][(2 * 15;);];Macros avec arguments. Elles se définissent par des expressions de la forme :
#define nom(ident1, ... identk) corpsIl ne doit pas y avoir de blanc entre le nom de la macro et la parenthèse ouvrante. Comme précédemment, le corps de la macro s'étend jusqu'à la fin de la ligne. Les identificateurs entre parenthèses sont les arguments de la macro ; ils apparaissent aussi dans le corps de celle-ci. Les utilisations (on dit les appels) de la macro se font sous la forme
nom(texte1, ... textek)Cette expression sera remplacée par le corps de la macro, dans lequel ident1 aura été remplacé par texte1, ident2 par texte2, etc. Exemple 65 :
#define permuter(a, b, type) { type w_; w_ = a; a = b; b = w_; }Exemple d'appel :
permuter(t[i], t[j], short *)Résultat de la substitution (on dit aussi développement) de la macro :
{ short * w_; w_ = t[i]; t[i] = t[j]; t[j] = w_; }Les appels de macros ressemblent beaucoup aux appels de fonctions. La même facilité, ne pas récrire un certain code source, peut être obtenue avec une macro et avec une fonction. Mais il faut comprendre que ce n'est pas du tout la même chose. Alors que le corps d'une fonction figure en un seul exemplaire dans le programme exécutable dont elle fait partie, le corps d'une macro est recopié puis compilé à chaque endroit ou figure l'appel de la macro.
Il faut donc que le corps d'une macro soit réduit, sans quoi son utilisation peut finir par être très onéreuse en termes d'espace occupé. Un autre inconvénient des macros est que leur définition « hors syntaxe » les rend très difficiles à maitriser au-delà d'un certain degré de complexité (pas de variables locales, etc.).
En faveur des macros : leur efficacité. Le texte de la macro étant recopié à la place de l'appel, on gagne à chaque fois le coût d'un appel de fonction. Il eût été bien peu efficace d'appeler une fonction pour ne faire que la permutation de deux variables ! Autre intérêt des macros, elles sont indépendantes des types de leurs arguments ou même, comme ci-dessus, elles peuvent avoir un type pour argument.
En définitive, la principale utilité des macros est d'améliorer l'expressivité et la portabilité des programmes en centralisant la définition d'opérations compliquées, proches du matériel ou sujettes à modification. Voici un exemple élémentaire : en C original (dans lequel on ne dispose pas du type void *) la fonction malloc doit être généralement utilisée en association avec un changement de type :
p = (machin *) malloc(sizeof(machin));Des telles expressions peuvent figurer à de nombreux endroits d'un programme. Si nous définissons la macro
#define NOUVEAU(type) ((type *) malloc(sizeof(type)))alors les allocations d'espace mémoire s'écriront de manière bien plus simple et expressive
p = NOUVEAU(machin);De plus, un éventuel remplacement ultérieur de malloc par un autre procédé d'obtention de mémoire sera facile et fiable, puisqu'il n'y aura qu'un point du programme à modifier.
Attention
1. Il est quasiment obligatoire d'écrire les arguments et le corps des macros entre parenthèses, pour éviter des problèmes liés aux priorités des opérateurs. Par exemple, la macro
#define TVA(p) 0.196 * pest très imprudente, car une expression comme (int) TVA(x) sera développée en (int) 0.196 * x, ce qui vaut toujours 0. Première correction :
#define TVA(p) (0.186 * p)Le problème précédent est corrigé, mais il y en a un autre : l'expression TVA(p1 + p2) est développée en (0.186 * p1 + p2), ce qui est probablement erroné. D'où la forme habituelle :
#define TVA(p) (0.186 * (p))2. Il ne faut jamais appeler une macro inconnue avec des arguments qui ont un effet de bord, car ceux-ci peuvent être évalués plus d'une fois. Exemple classique : on dispose d'une macro nommée toupper qui transforme toute lettre minuscule en la majuscule correspondante, et ne fait rien aux autres caractères. Elle pourrait être ainsi définie (mais on n'est pas censé le savoir) :
#define toupper(c) ('a' <= (c) && (c) <= 'z' ? (c) + ('A' - 'a') : (c))On voit que l'évaluation de toupper(c) comporte au moins deux évaluations de c. Voici un très mauvais appel de cette macro :
calu = toupper(getchar())En effet, cette expression se développe en
calu = ('a' <= (getchar()) && (getchar()) <= 'z'
? (getchar()) + ('A' - 'a') : (getchar()));A chaque appel, au moins deux caractères sont lus, ce qui n'est sûrement pas l'effet recherché. On notera que si toupper avait été une fonction, l'expression toupper(getchar()) aurait été tout à fait correcte. Mais puisque ce n'en est pas une, il faut l'appeler avec un argument sans effet de bord. Par exemple :
{ calu = getchar(); calu = toupper(calu); }62Le mot macro est une abréviation de l'expression « macro-instruction » désignant un mécanisme qui existe depuis longtemps dans beaucoup d'assembleurs. Les macros avec arguments sont appelées aussi pseudo-fonctions.
63Mais il découle de la section 1.2.1 que le corps d'une macro peut occuper en fait plusieurs lignes : il suffit que chacune d'elles, sauf la dernière, se termine par le caractère n.
64Pour permettre de trouver ce genre d'erreurs, certains compilateurs C possèdent une option (sous UNIX l'option -E) qui produit l'affichage du programme source uniquement transformé par le préprocesseur.
65Dans cet exemple, les accolades f et g donnent au corps de la macro une structure de bloc qui sera comprise et exploitée par le compilateur, mais cette structure est parfaitement indifférente au préprocesseur.
VIII-A-3. Compilation conditionnelle▲
Les directives de conditionnelle (compilation) se présentent sous les formes suivantes :

La partie else est facultative ; on a donc droit aussi aux formes :
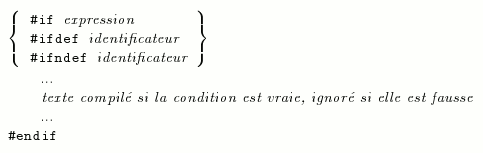
Lorsque le premier élément de cette construction est #if expression, expression doit pouvoir être évaluée par le préprocesseur. Ce doit donc être une expression constante ne contenant pas l'opérateur de changement de type ni les opérateurs sizeof ou &. Elle sera évaluée et
- si elle est vraie, c'est-à-dire non nulle, alors le texte qui se trouve entre #if et #else sera traité par le compilateur, tandis que celui qui figure entre #else et #endif sera purement et simplement tenu pour inexistant ;
- si elle est fausse, c'est-à-dire nulle, c'est le premier texte qui sera ignoré tandis que le second sera lu par le compilateur. Dans la forme sans #else, si la condition est fausse aucun texte ne sera compilé.
Les directives
#ifdef identificateur
#ifndef identificateuréquivalent respectivement à
#if « identificateur est le nom d'une macro actuellement définie »
#if « identificateur n'est pas le nom d'une macro actuellement définie »La compilation conditionnelle se révèle être un outil précieux pour contrôler les parties des programmes qui dépendent de la machine ou du système sous-jacent. On obtient de la sorte des textes sources qui restent portables malgré le fait qu'ils contiennent des éléments non portables. Voici un exemple : les fonctions de lecture- écriture sur des fichiers binaires ne sont pas les mêmes dans la bibliothèque ANSI et dans la bibliothèque UNIX classique. Une manière d'écrire un programme indépendant de ce fait consiste à enfermer les appels de ces fonctions et les déclarations qui s'y rapportent dans des séquences conditionnelles.
Déclaration :
...
#ifdef BINAIRES_ANSI
FILE *fic;
#else
int fic;
#endif
...Ouverture :
...
#ifdef BINAIRES_ANSI
fic = fopen(nom, "r");
ok = (fic != NULL);
#else
fic = open(nom, 0);
ok = (fic >= 0);
#endif
...Lecture :
...
#ifndef BINAIRES_ANSI
ok = (fread(&art, sizeof(art), 1, fic) == 1);
#else
ok = (read(fic, &art, sizeof(art)) == sizeof(art));
#endif
...L'emploi de la compilation conditionnelle associée à la définition de noms de macros est rendu encore plus commode par le fait qu'on peut utiliser
- des noms de macros normalement définis (#define...) ;
- des noms de macros définis dans la commande qui lance la compilation, ce qui permet de changer le texte qui sera compilé sans toucher au fichier source. De plus, puisque ces définitions se font au niveau de la commande de compilation, elles pourront être faites par des procédures de commandes (scripts) donc automatisées ;
- un ensemble de noms de macros prédéfinis dans chaque système, pour le caractériser. Par exemple dans le compilateur des systèmes UNIX la macro UNIX est définie et vaut 1.
Remarque. Le préprocesseur du C ANSI offre également l'opérateur defined qui permet d'écrire les directives #ifdef ident (resp. #ifndef ident) sous la forme #if defined ident (resp. #if !defined ident).
D'autre part, la construction
#if expression1
...
#else
#if expression2
...
#endif
#endifpeut en C ANSI s'abréger en
#if expression1
...
#elif expression2
...
#endifVIII-B. La modularité de C▲
A ce point de notre exposé nous pouvons nous poser une question importante : le langage C est-il modulaire ? La modularité est une qualité que les bonnes méthodes de conception doivent posséder. Elle n'est pas facile à définir ; on peut toutefois la cerner à travers quelques critères 66.
Une méthode de conception doit
- aider à diviser chaque nouveau problème en sous-problèmes qu'on peut résoudre séparément (critère de décomposabilité) ;
- favoriser la production de composants logiciels qui peuvent se combiner librement pour produire de nouveaux systèmes (critère de composabilité) ;
- permettre au concepteur d'écrire des modules dont chacun peut être compris isolément par un lecteur humain (critère de compréhensibilité) ;
- permettre qu'une petite modification des spécifications du problème entraine uniquement la modification d'un petit nombre des modules de la solution (critère de continuité) ;
- assurer que l'effet d'une condition anormale se produisant dans un module restera localisé à ce module ou, au pire, n'atteindra qu'un petit nombre de modules « voisins » ( critère de protection).
Théoriquement, tout langage de programmation peut servir à mettre en ¾uvre une méthode de conception modulaire, mais dans certains cas il faut une telle dose de ruse et d'autodiscipline, pour un résultat si peu fiable, que le jeu n'en vaut pas la chandelle. En pratique un langage est dit modulaire lorsqu'on peut, sans douleur et sans artifice, en faire l'outil d'une méthode de conception modulaire. L'expérience montre que les critères précédents induisent sur le langage en question quelques contraintes assez précises, comme celles-ci :
- les modules doivent correspondre à des entités syntaxiques du langage ;
- chaque module doit partager des informations avec aussi peu d'autres modules que possible, et quand un tel partage existe il doit concerner aussi peu d'éléments que possible ;
- quand deux modules partagent des informations, cela doit être clairement indiqué dans leurs deux textes.
A la lumière de ces principes la modularité de C apparait fort rudimentaire, pour ne pas dire inexistante. Si l'on prend pour modules les fichiers sources qui composent un programme, on constate qu'aucune structure syntaxique ne signale les modules ni n'en délimite la portée, d'autant plus que le caractère non syntaxique de la directive #include brouille l'organisation du programme en fichiers distincts. Aucune déclaration particulière n'est requise pour indiquer que des objets sont partagés entre plusieurs modules. Chaque module communique avec tous les autres et, sauf spécification contraire, tous les objets de chaque module sont partagés.
Bien sûr, la compilation séparée est une des idées-clés du langage, et il est possible de rendre inaccessibles les noms qui peuvent être privés. Mais le langage offre peu d'outils pour rendre fiable le partage des noms qui doivent être publics, et ces outils restent d'un emploi facultatif, subordonné à l'autodiscipline du programmeur.
Par exemple, si dans un module B on doit référencer une variable ou une fonction définie dans un module A, il suffit d'écrire dans B une déclaration comme extern int x ;. Cet énoncé postule l'existence d'un objet nommé x, ce qui sera contrôlé par l'éditeur de liens. Mais il donne à x des attributs (la classe variable, le type int) que l'objet désigné par x ne possède pas forcément ; aucune vérification cependant ne sera faite. Ainsi la compilation de B se fait dans la plus totale insécurité.
66Suivant l'analyse de Bertrand Meyer (Conception et programmation par objets, InterEditions, 1990) à laquelle il semble difficile d'ajouter ou de retrancher quelque chose.
VIII-B-1. Fichiers en-tête▲
Le seul moyen dont dispose l'auteur d'un module A pour s'assurer que les autres modules qui forment un programme utilisent correctement les variables et fonctions qu'il rend publiques consiste à écrire un fichier entête (fichier A.h) contenant toutes les déclarations publiques. Ce fichier doit être inclus par la directive #include dans le module qui implante les objets publics (fichier A.c) et dans chacun des modules qui les utilisent. De cette manière tous ces fichiers « voient » les mêmes définitions de types, les mêmes déclarations de variables et les mêmes prototypes de fonctions ; ces déclarations sont écrites en un seul endroit, et toute modification de l'une d'entre elles se répercute sur tous les fichiers qui en dépendent.
La nécessité de ces fichiers en-tête apparait encore plus grande quand on considère le cas des bibliothèques, c'est-à-dire des modules que leurs fonctionnalités placent en position de prestataires de services vis-à-vis des autres modules qui composent un programme ; on parle alors de module serveur et de modules clients. En fait, on peut presque toujours voir la modularité en termes de serveurs et clients, car il y a toujours une hiérarchie parmi les modules. Le propre des bibliothèques est d'être conçues de manière indépendante des clients, afin de pouvoir être utilisées dans un programme présent et un nombre quelconque de programmes futurs. L'intérêt de leur associer le meilleur dispositif pour minimiser le risque de mauvaise utilisation est évident.
Typiquement, un fichier en-tête comportera les éléments suivants :
- Des directives #include concernant les autres fichiers en-tête nécessaires pour la compréhension (par le compilateur) des éléments qui apparaissent dans le fichier en-tête en question.
- Des définitions de constantes, soit sous forme de directives #define soit sous forme de type énuméré, qui sont des informations symboliques échangées entre le serveur et ses clients. Exemple : dans une bibliothèque graphique, les noms conventionnels des couleurs.
- Des définitions de structures (struct, union) et de types (typedef) qui définissent la nature des objets manipulés par la bibliothèque. Typiquement, ces types permettent aux clients de déclarer les objets qui sont les arguments et les résultats des fonctions de la bibliothèque. Exemple : dans une bibliothèque graphique, la définition de types point, segment, etc.
- Les déclarations extern des variables publiques du serveur. Les définitions correspondantes (sans le qualifieur extern) figureront dans le module serveur.
Remarque. L'emploi de variables publiques est déconseillé ; un module ne devrait offrir que des fonctions 67.
- Les déclarations des fonctions publiques du serveur. Les définitions correspondantes figureront dans le module serveur. En syntaxe originale seules les déclarations des fonctions qui ne rendent pas un entier sont nécessaires, mais même dans ce cas c'est une bonne habitude que d'y mettre les déclarations de toutes les fonctions, cela constitue un germe de documentation.
Bien entendu, tous les noms de variables et fonctions du module serveur qui ne figurent pas dans le fichier en-tête doivent être rendus privés (en les qualifiant static).
67S'il est utile qu'un client puisse consulter ou modifier une variable du serveur, écrivez une fonction qui ne fait que cela (mais en contrôlant la validité de la consultation ou de la modification). C'est bien plus sûr que de donner libre accès à la variable.
VIII-B-2. Exemple : stdio.h▲
A titre d'exemple visitons rapidement le plus utilisé des fichiers en-tête de la bibliothèque standard : stdio.h.
Notre but n'est pas de prolonger ici l'étude des entrées-sorties, mais d'illustrer les indications du paragraphe précédent sur l'écriture des fichiers en-tête. Le texte ci-après est fait de morceaux de la version MPW (Macintosh Programmer Workshop) du fichier stdio.h auquel nous avons enlevé ce qui ne sert pas notre propos :
/* stdIO.h -- Standard C I/O Package
* Modified for use with Macintosh C
* Apple Computer, Inc. 1985-1988
*
* Copyright American Telephone & Telegraph
* Used with permission, Apple Computer Inc. (1985)
* All rights reserved.
*/
#ifndef __STDIO__ /* Voir le renvoi 1 ci-dessous */
#define __STDIO__
#include <stddef.h>
#include <stdarg.h>
/*
* Miscellaneous constants
*/
#define EOF (-1)
#define BUFSIZ 1024
#define SEEK_SET 0
#define SEEK_CUR 1
#define SEEK_END 2
/*
* The basic data structure for a stream is the FILE.
*/
typedef struct { /* Voir le renvoi 2 ci-dessous */
int _cnt;
unsigned char *_ptr;
unsigned char *_base;
unsigned char *_end;
unsigned short _size;
unsigned short _flag;
unsigned short _file;
} FILE;
/*
* Things used internally:
*/
extern FILE _iob[]; /* Voir le renvoi 3 ci-dessous */
int _filbuf (FILE *);
int _flsbuf (int, FILE *);
/*
* The standard predefined streams
*/
#define stdin (&_iob[0])
#define stdout (&_iob[1])
#define stderr (&_iob[2])
/*
* File access functions
*/
int fclose (FILE *); /* Voir le renvoi 4 ci-dessous */
int fflush (FILE *);
FILE *fopen (const char *, const char *);
int setvbuf (FILE *, char *, int, size_t);
/*
* Formatted input/output functions
*/
int printf (const char *, ...); /* Voir le renvoi 5 ci-dessous */
int fprintf (FILE *, const char *, ...);
int sprintf (char *, const char *, ...);
int scanf (const char *, ...);
int fscanf (FILE *, const char *, ...);
int sscanf (const char *, const char *, ...);
/*
* Character input/output functions and macros
*/
int fgetc (FILE *);
int ungetc (int, FILE *);
int fputc (int, FILE *);
char *fgets (char *, int, FILE *);
char *gets (char *);
int puts (const char *);
int fputs (const char *, FILE *);
#define getc(p) (--(p)->_cnt >= 0 \
? (int) *(p)->_ptr++ : _filbuf(p))
#define getchar() getc(stdin)
#define putc(x, p) (--(p)->_cnt >= 0 \
? ((int) (*(p)->_ptr++ = (unsigned char) (x))) \
: _flsbuf((unsigned char) (x), (p)))
#define putchar(x) putc((x), stdout)
/*
* Direct input/output functions
*/
size_t fread (void *, size_t, size_t, FILE *);
size_t fwrite (const void *, size_t, size_t, FILE *);
#endif __STDIO__Renvois :
1. Lorsque les fichiers en-tête sont d'un intérêt général ils finissent par être inclus dans de nombreux autres fichiers, eux-mêmes inclus les uns dans les autres. Le compilateur risque alors de lire plusieurs fois un même fichier, ce qui entraine un travail inutile et parfois des erreurs liées à des redéfinitions. Par exemple, imaginons que MonBazar.h soit un fichier comportant la directive #include <stdio.h>. Dans la compilation d'un fichier commençant par les deux directives
#include <stdio.h>
#include "MonBazar.h"le compilateur risquerait de compiler deux fois le fichier stdio.h. Les deux premières directives de ce fichier résolvent ce problème : lorsque ce fichier est pris en compte une première fois, le nom __STDIO__ (nom improbable arbitrairement associé à stdio.h) devient défini. Durant la présente compilation, la directive #ifndef __STDIO__ fera que l'intérieur du fichier ne sera plus jamais lu par le compilateur. Tous les fichiers en-tête peuvent être protégés de cette manière contre les inclusions multiples.
2. On peut noter ici que la vue du type FILE qu'ont les modules clients est très différente de celle qu'ils auraient en utilisant un langage très modulaire comme Modula II ou Ada. Dans ces langages les noms et les types des champs d'une structure comme FILE resteraient privés, ainsi que la structure elle-même ; seul le type adresse d'une telle structure serait rendu public. Cela s'appelle un type opaque et augmente la fiabilité des programmes.
En C nous n'avons pas d'outils pour procéder de la sorte : ou bien un type est privé, connu uniquement du module serveur, ou bien il faut « tout dire » à son sujet. L'utilisation d'un pointeur générique, dans le style de
typedef void *FILE_ADDRESS;dissimulerait bien l'information sur la structure FILE, mais aurait la conséquence de rendre impossibles à déceler les mauvaises utilisations du type en question par le client. Notez d'autre part que la connaissance dans les modules clients des noms des champs de la structure FILE est indispensable pour l'utilisation des macros comme getc ou putc.
3. Tous les noms qui apparaissent dans le fichier en-tête deviennent de ce fait publics, même ceux qu'on aurait aimé garder privés alors qu'on ne le peut pas, par exemple parce qu'ils apparaissent dans le corps d'une macro, comme ici le nom de la table des descripteurs de fichiers iob. Le langage C n'ayant rien prévu à ce effet, la « privacité » n'est assurée que par une convention entre le système et les utilisateurs : tout nom commençant par un blanc souligné « » appartient au système et l'utilisateur doit feindre d'en ignorer l'existence.
4. Ceci n'est pas la meilleure manière de donner les prototypes des fonctions dans un fichier en-tête. Dans une déclaration qui n'est pas une définition, la syntaxe n'exige pas les noms des arguments mais uniquement leurs types. Cependant, s'ils sont bien choisis, ces noms apportent une information supplémentaire qui augmente la sécurité d'utilisation de la bibliothèque. Par exemple, les prototypes
FILE *fopen(const char *, const char *);
size_t fread(void *, size_t, size_t, FILE *);ne seraient d'aucune utilité à un programmeur qui hésiterait à propos du rôle ou de l'ordre des arguments de ces fonctions, contrairement à leurs versions « équivalentes » :
FILE *fopen(const char *filename, const char *mode);
size_t fread(void *buffer, size_t size, size_t count, FILE *stream);5. Les appels de fonctions avec des arguments variables ne bénéficient pas des vérifications syntaxiques que le C ANSI effectue lorsque la fonction a fait l'objet d'une définition de prototype. Sauf pour les arguments nommés (le premier ou les deux premiers), les arguments que l'on passe à l'une de ces six fonctions échappent donc à tout contrôle du compilateur. L'information concernant la nature de ces arguments est portée par le format ; elle ne pourra être exploitée qu'à l'exécution.
Autres remarques :
Le premier client de ce dispositif doit être le fournisseur lui-même. Pour que la protection contre l'erreur recherchée soit effective, il faut que chacun des fichiers qui réalisent l'implantation des variables et fonctions « promises » dans stdio.h comporte la directive
#include <stdio.h>De cette manière on garantit que l'auteur et l'utilisateur de chaque variable ou fonction sont bien d'accord sur la définition de l'entité en question.
Une autre règle à respecter par l'auteur du ou des modules serveurs : qualifier static tous les noms qui ne sont pas déclarés dans le fichier en-tête, pour éviter les collisions de noms. Le fichier en-tête joue ainsi, pour ce qui concerne les variables et les fonctions, le rôle de liste officielle des seuls noms publics.
VIII-C. Deux ou trois choses bien pratiques...▲
VIII-C-1. Les arguments du programme principal▲
Cette section ne concerne que les environnements, comme UNIX ou MS-DOS, dans lesquels les programmes sont activés en composant une commande de la forme nom-du-programme argument1 ... argumentk.
L'exécution d'un programme commence par la fonction main. Tout se passe comme si le système d'exploitation avait appelé cette fonction comme une fonction ordinaire. Il faut savoir que lors de cet appel, des arguments sont fournis au programme. Voici l'en-tête complet de main, en syntaxe ANSI :
int main(int argc, char *argv[])avec :
- argc : nombre d'arguments du programme
- argv : tableau de chaines de caractères, qui sont les arguments du programme. Par convention, le premier argument est le nom du programme lui-même.
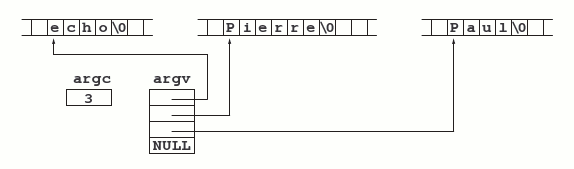
Imaginons avoir écrit un programme qui, une fois compilé, se nomme echo ; supposons que ce programme soit lancé par la commande :
echo Pierre Paulalors, main reçoit les arguments que montre la figure 18.
Supposons que tout ce que l'on demande à echo soit de recopier la liste de ses arguments. Voici comment on pourrait écrire ce programme :
main(int argc, char *argv[]) {
int i;
for (i = 0; i < argc; i++)
printf("%s\n", argv[i]);
return 0;
}La frappe de la commande « echo Pierre Paul » produit l'affichage de
echo
Pierre
PaulLa principale application de ce mécanisme est la fourniture à un programme des paramètres dont il peut dépendre, comme des noms de fichiers, des tailles de tableaux, etc. Par exemple, voici une nouvelle version du programme de copie de fichiers donné à la section 7.4.1, qui prend les noms des fichiers source et destination comme arguments :
#include <stdio.h>
#define PAS_D_ERREUR 0
#define ERREUR_OUVERTURE 1
#define ERREUR_CREATION 2
#define PAS_ASSEZ_D_ARGUMENTS 3
FILE *srce, *dest;
main(int argc, char *argv[]) {
char tampon[512];
int nombre;
if (argc < 3)
return PAS_ASSEZ_D_ARGUMENTS;
if ((srce = fopen(argv[1], "rb")) == NULL)
return ERREUR_OUVERTURE;
if ((dest = fopen(argv[2], "wb")) == NULL)
return ERREUR_CREATION;
while ((nombre = fread(tampon, 1, 512, srce)) > 0)
fwrite(tampon, 1, nombre, dest);
fclose(dest);
return PAS_D_ERREUR;
}Si nous appelons copier le fichier exécutable produit en compilant le texte ci-dessus, alors nous pourrons l'exécuter en composant la commande
copier fichier-source fichier-destinationVIII-C-2. Branchements hors fonction : setter.h▲
Le mécanisme des longs branchements permet d'obtenir la terminaison immédiate de toutes les fonctions qui ont été appelées (et ne sont pas encore terminées) depuis que le contrôle est passé par un certain point du programme, quel que soit le nombre de ces fonctions. Il est réalisé à l'aide des deux fonctions :
int setter(jmp_buf contexte); void
longjmp(jmp_buf contexte, int code);Cela fonctionne de la manière suivante : tout d'abord il faut déclarer une variable, généralement globale, de type jmp buf (type défini dans le fichier en-tête setter.h) :
#include <setter.h>
...
jmp_buf contexte;L'appel
setter(contexte);enregistre dans contexte certaines informations traduisant l'état du système, puis renvoie zéro. Ensuite, l'appel
longjmp(contexte, valeur);remet le système dans l'état qui a été enregistré dans la variable contexte. Plus précisément, le système se trouve comme si l'appel de setter(contexte) venait tout juste de se terminer, en rendant cette fois non pas zéro mais la valeur indiquée dans l'appel de longjmp.
Le principal service rendu par ce dispositif est de permettre de programmer simplement, et en maitrisant le « point de chute », l'abandon d'une famille de fonctions qui se sont mutuellement appelées. Examinons un exemple classique : supposons qu'une certaine fonction expression soit un analyseur syntaxique présentant deux caractéristiques fréquentes :
- la fonction expression est à l'origine d'une imbrication dynamique fort complexe (expression appelle une fonction terme, qui appelle une fonction facteur qui à son tour appelle une fonction primaire laquelle rappelle expression, etc.) ;
- chacune des fonctions expression, terme, facteur, etc., peut à tout moment rencontrer une erreur dans ses données, qui rend la poursuite du traitement inutile ou impossible.
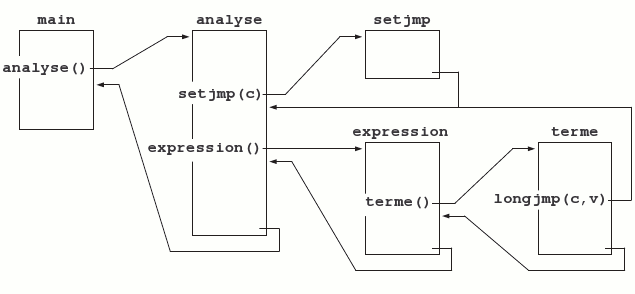
Voici comment l'appel d'expression pourrait être emballé dans une fonction « enveloppe » nommée analyse (voir la figure 19) :
#include <setter.h>
...
jmp_buf contexte;
...
int analyse(void) {
if (setter(contexte) == 0) {
expression();
return SUCCES;
}
else
return ERREUR;
}Fonctionnement : lorsque la fonction analyse est activée, setter est appelée et rend 0 ; elle est donc immédiatement suivie par l'appel de expression. Si le travail de expression se termine normalement, alors analyse rendra SUCCES et elle aura été transparente. D'autre part, dans la fonction expression et toutes celles appelées « au-dessus » d'elle (terme, facteur, etc.), il est possible d'effectuer l'appel
longjmp(contexte, 1);qui ramène le contrôle dans la fonction analyse, exactement sur la partie condition de l'instruction
if (setter(contexte) == 0)mais cette fois la valeur rendue par setter sera 1 et analyse rendra donc la valeur ERREUR. Remarques :
- L'appel de longjmp se présente comme une remise du système dans l'un des états par lesquels il est passé. Cela est vrai, sauf pour ce qui concerne la valeur des variables, notamment les variables globales : elles ne reprennent pas la valeur qu'elles avaient lorsque longjmp a été appelée.
- On ne peut effectuer un appel de longjmp que pour ramener le système dans l'une des fonctions appelées et non encore terminées, pour laquelle l'espace local est encore alloué dans la pile. Appeler longjmp avec un contexte qui a été mémorisé dans une fonction dont l'activation est terminée est une erreur aux conséquences indéfinies, même si cette fonction a été rappelée depuis. Par exemple, un appel longjmp(c,v) qui serait placé dans la fonction main après l'appel analyse() (voir la figure 19) serait erroné, car il utiliserait le contexte d'une activation de fonction (la fonction analyse) qui n'existe plus.
VIII-C-3. Interruptions : signal.h▲
L'objet de la fonction signal est la détection d'événements asynchrones qui peuvent se produire pendant l'exécution d'un programme. « Asynchrones » signifie qu'on ne peut pas prévoir le moment ou ils se produiront, car ils ne résultent pas d'instructions normalement insérées dans la séquence qui forme le programme.
Un certain ensemble de types d'événements, dépendant de chaque système, est récupérable à travers le mécanisme décrit ici. En général on traite de la même manière le vrai et le faux asynchronisme. Une coupure de courant ou une interruption provoquée par l'utilisateur sont des événements vraiment imprévisibles. Une référence à travers un pointeur invalide ou une division par zéro ne sont pas réellement asynchrones (si on avait connu parfaitement le programme et les données on aurait pu prédire très exactement de tels événements), mais il est commode de les considérer comme tels et de les récupérer de la même manière.
La fonction signal est déclarée dans le fichier signal.h de la façon suivante :
void (*signal(int numero, void (*manip)(int)))(int);Ce prototype n'est pas très facile à lire. Définissons le type PROCEDURE comme celui d'une fonction sans résultat défini ayant un argument de type int :
typedef void PROCEDURE(int);Avec cela, la déclaration précédente se récrit plus simplement :
PROCEDURE *signal(int numero, PROCEDURE *manip);et elle nous apprend que la fonction signal prend deux arguments, à savoir un int et l'adresse d'une PROCEDURE, et renvoie l'adresse d'une PROCEDURE.
Lors d'un appel de signal, l'argument numero doit désigner un des événements qu'il est possible de récupérer. L'effet de signal est d'enregistrer la PROCEDURE donnée en argument, de telle manière que si l'événement en question se produit, alors elle sera automatiquement appelée par le système avec pour argument le numéro de l'événement. La fonction signal rend l'adresse de la PROCEDURE qui était jusqu'alors enregistrée pour ce même événement.
Six événements sont prévus par le standard ANSI (ils ne sont pas tous implantés dans tous les systèmes ; en outre, chaque système peut ajouter ses propres particularités) :
- SIGABRT : fin anormale du programme (appel de la fonction abort)
- SIGINT : interruption provoquée par l'utilisateur (touche Ctrl-C, etc.)
- SIGTERM : demande d'arrêt de l'utilisateur (interruption « forte »)
- SIGFPE : erreur arithmétique (division par zéro, etc.)
- SIGSEGV : accès mémoire illégal (souvent : mauvais pointeur dans l'accès à une donnée, débordement de tableau)
- SIGILL : instruction illégale (souvent : mauvais pointeur dans l'appel d'une fonction).
La bibliothèque fournit en outre deux mécanismes de récupération d'une interruption prédéfinis :
- SIG DFL : le mécanisme par défaut utilisé par le système pour l'événement en question lorsque la fonction signal n'a pas été appelée
- SIG IGN : le mécanisme trivial qui consiste à ignorer l'événement
Exemple. Supposons qu'une section d'un certain programme effectue des calculs très complexes dont la durée risque d'inquiéter l'utilisateur final. On souhaite donc offrir à ce dernier la possibilité d'interrompre le programme lorsqu'il estime que celui-ci devient excessivement long, en appuyant sur une touche particulière 68. L'utilisateur apprendra alors l'état d'avancement de son calcul (traduit par la valeur de la variable iteration_numero) et aura à choisir entre la continuation et la terminaison du programme :
#include <signal.h>
int iteration_numero;
typedef void PROCEDURE(int);
void voirSkissPass(int numero) {
int c;
printf("J'en suis a l'iteration: %d\nOn arrete? ", iteration_numero);
do
c = getchar();
while ((c = toupper(c)) != 'O' && c != 'N');
if (c == 'O')
exit(1); /* abandonner le programme */
else
return; /* reprendre le travail interrompu */
}
main() {
PROCEDURE *maniprec;
...
/* autres opérations */
...
/* entrée dans la section onéreuse */
maniprec = signal(SIGINT, voirSkissPass);
...
/* calculs terriblement complexes */
...
/* sortie de la section onéreuse */
signal(SIGINT, maniprec);
...
/* autres opérations */
...
}68Sur plusieurs systèmes, comme UNIX et VMS, il s'agit de la combinaison des deux touches « Ctrl » et « C ».
VIII-D. La bibliothèque standard▲
La bibliothèque standard ANSI se compose de deux sortes d'éléments :
- un ensemble de fichiers objets 69 contenant le code compilé des fonctions de la bibliothèque et participant, pour la plupart sans qu'il y soit nécessaire de l'indiquer explicitement, 70 à l'édition de liens de votre programme,
- un ensemble de fichiers en-tête contenant les déclarations nécessaires pour que les appels de ces fonctions puissent être correctement compilés.
Ces fichiers en-tête sont organisés par thèmes ; nous reprenons cette organisation pour expliquer les principaux éléments de la bibliothèque.
Des parties importantes de la bibliothèque standard ont déjà été expliquées ; notamment :
- la bibliothèque des entrées - sorties (associée au fichier stdio.h), à la section 7
- les listes variables d'arguments (introduites dans le fichier stdarg.h) à la section 4.3.4
- les branchements hors-fonction (déclarés dans le fichier setter.h) à la section 8.3.2
- la récupération des interruptions (avec le fichier signal.h) à la section 8.3.3.
Nous passerons sous silence certains modules mineurs (comme la gestion de la date et l'heure). Au besoin, reportez-vous à la documentation de votre système.
69Il s'agit en réalité de fichiers « bibliothèques » (extensions .a, .lib, .dll, etc.), mais de tels fichiers ne sont que des fichiers objets un peu arrangés pour en faciliter l'emploi par les éditeurs de liens.
70Notez que, sous UNIX, lorsque des fichiers de la bibliothèque standard ne sont pas implicites, il y a un moyen simple de les indiquer explicitement. Par exemple, l'option -lm dans la commande gcc spécifie l'apport de la bibliothèque /lib/libm.a (ce fichier contient le code des fonctions mathématiques).
VIII-D-1. Aide à la mise au point : assert.h▲
Cette « bibliothèque » ne contient aucune fonction. Elle se compose d'une macro unique :
void assert(int expression)qui fonctionne de la manière suivante : si l'expression indiquée est vraie (c'est-à-dire non nulle) au moment ou la macro est évaluée, il ne se passe rien. Si l'expression est fausse (c.-à-d. si elle vaut zéro), un message est imprimé sur stderr, de la forme
Assertion failed: expression, file fichier, line numeroensuite l'exécution du programme est avortée. Exemple naïf :
#include <assert.h>
...
#define TAILLE 100
int table[TAILLE];
...
for (i = 0; j < TAILLE; i++) {
...
assert(0 <= i && i < TAILLE);
table[i] = 0;
...
}l'exécution de ce programme donnera (puisqu'une faute de frappe a rendu infinie la boucle for ) :
Assertion failed: 0 <= i && i < TAILLE, file ex.c, line 241La macro assert est un outil précieux pour la mise au point des programmes. Sans elle, il arrive souvent qu'une situation anormale produite en un point d'un programme ne se manifeste qu'en un autre point sans rapport avec avec le premier ; il est alors très difficile de remonter depuis la manifestation du défaut jusqu'à sa cause. Beaucoup de temps peut être gagné en postant de telles assertions aux endroits « délicats », ou les variables du programme doivent satisfaire des contraintes cruciales.
Il est clair, cependant, que cet outil s'adresse au programmeur et n'est utile que pendant le développement du programme. Les appels de assert ne doivent pas figurer dans l'exécutable livré à l'utilisateur final, pour deux raisons : d'une part, ce dernier n'a pas à connaitre des détails du programme source (en principe il ne connait même pas le langage de programmation employé), d'autre part parce que les appels de assert ralentissent les programmes.
Lorsque la mise au point d'un programme est terminée, on doit donc neutraliser tous les appels de assert qui y figurent. Cela peut s'obtenir en une seule opération, simplement en définissant en tête du programme 71 l'identificateur NDEBUG :
#define NDEBUG peu importe la valeurjuste avant d'effectuer la compilation finale du programme. Celle-ci se fera alors comme si tous les appels de assert avaient été gommés.
N.B. Le fait qu'il soit possible et utile de faire disparaitre les appels de assert du programme exécutable final montre bien que assert n'est pas la bonne manière de détecter des erreurs que le programmeur ne peut pas éviter, comme les erreurs dans les données saisies. Ainsi - sauf pour un programme éphémère à usage strictement personnel - le code suivant n'est pas acceptable :
...
scanf("%d", &x);
assert(0 <= x && x <= N); /* NON ! */
...La vérification que 0 <= x && x <= N porte sur une valeur lue à l'exécution et garde tout son intérêt dans le programme final, lorsque les assert sont désarmés. C'est pourquoi elle doit plutôt être programmée avec du « vrai » code :
...
scanf("%d", &x);
if( ! (0 <= x && x <= N)) {
fprintf(stderr, "Erreur. La valeur de x doit être comprise entre 0 et %d\n", N);
exit(-1);
}
...71Sous UNIX il n'est même pas nécessaire d'ajouter une ligne au programme : il suffit de composer la commande gcc en spécifiant une option « -D », comme ceci : gcc -DNEBUG -o monprog monprog.c etc.
VIII-D-2. Fonctions utilitaires : stdlib.h▲
atoi
int atoi(const char *s), long atol(const char *s), double atof(const char *s)Ces fonctions calculent et rendent l'int (resp. le long, le double) dont la chaine s est l'expression écrite.
Exemple :
int i;
char *s;
...
/* affectation de s */
...
i = atoi(s);
/* maintenant i a la valeur numérique dont la chaine s est l'expression textuelle */Note. Pour faire le travail inverse de atoi ou une autre des fonctions précédentes on peut employer sprintf selon le schéma suivant :
int i;
char s[80];
...
/* affectation de i */
...
sprintf(s, "%d", i);
/* maintenant la chaine s est l'expression textuelle de la valeur de i */ rand
int rand(void)Le ieme appel de cette fonction rend le ieme terme d'une suite d'entiers pseudo-aléatoires compris entre 0 et la valeur de la constante RAND MAX, qui vaut au moins 32767. Cette suite ne dépend que de la valeur de la semence donnée lors de l'appel de srand, voir ci-dessous. Si srand n'a pas été appelée, la suite obtenue est celle qui correspond à srand(1). Voyez srand ci-après.
srand
void srand(unsigned int semence)Initialise une nouvelle suite pseudo-aléatoire, voir rand ci-dessus. Deux valeurs différentes de la semence { éloignées ou proches, peu importe { donnent lieu à des suites tout à fait différentes, du moins à partir du deuxième terme.
Application. Pour que la suite aléatoire fournie par les appels de rand que fait un programme soit différente à chaque exécution de ce dernier il fait donc commencer par faire un appel de srand en veillant à lui passer un argument différent chaque fois. Une manière d'obtenir cela consiste à utiliser l'heure courante (elle change tout le temps !), par exemple à travers la fonction time 72. Par exemple, le programme suivant initialise et affiche une suite pseudo-aléatoire de dix nombres flottants xi vérifiant 0 ≤ xi ≤ 1 :
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
main() {
int i;
float x;
srand(time(NULL)); /* version C de randomize */
rand(); /* le premier tirage est très lié à la semence */
for(i = 0; i < 10; i++) {
x = rand() / (float) RAND_MAX;
printf("%f\n", x);
}
} malloc
void *malloc(size t taille)Alloue un espace pouvant mémoriser un objet ayant la taille indiquée, ou NULL en cas d'échec. Cet espace n'est pas initialisé.
calloc
void *calloc(size t nombre, size t taille)Alloue un espace suffisant pour loger un tableau de nombre objets, chacun ayant la taille indiquée, ou NULL en cas d'échec. L'espace alloué est initialisé par des zéros.
free
void free(void *adresse)Indique au système que l'espace mémoire ayant l'adresse indiquée n'est plus utile au programme. Cette adresse doit nécessairement provenir d'un appel de malloc, calloc ou realloc.
realloc
void *realloc(void *adr, size t taille)Ré-allocation d'espace. La valeur de adr doit provenir d'un appel de malloc, calloc ou realloc. Cette fonction essaie d'agrandir ou de rétrécir (usage rare) l'espace pointé par adr afin qu'il ait la la taille demandée. Si cela peut se faire sur place alors la fonction renvoie la même adresse adr. Sinon, elle obtient un nouvel espace ayant la taille voulue, y copie le contenu de l'espace pointé par adr, libère cet espace, enfin renvoie l'adresse de l'espace nouvellement alloué.
exit
void exit(int code)Produit l'arrêt normal (fermeture des fichiers ouverts, etc.) du programme. La valeur du code indiqué est transmise au système d'exploitation, cette valeur est utilisée lorsque le programme a été appelé dans le cadre d'un procédure de commandes (ou script). La signification de ce code dépend du système ; on peut utiliser les constantes :
- EXIT SUCCESS : la valeur conventionnelle qui indique, pour le système sous-jacent, que le programme a réussi à accomplir sa mission
- EXIT FAILURE : le programme n'a pas réussi
abort
void abort(void)Provoque un arrêt anormal du programme (c'est un événement détecté par la fonction signal).
system
int system(const char *commande)Suspend momentanément l'exécution du programme en cours, demande à l'interprète des commandes du système d'exploitation d'exécuter la commande indiquée et rend le code donné par cette commande (cette valeur dépend du système). La chaine commande doit être l'expression complète, avec options et arguments, d'une commande légale pour le système utilisé.
Toutes les versions de C n'offrent pas ce service, mais on peut savoir ce qu'il en est : l'appel system(NULL) rend une valeur non nulle si l'interprète de commandes peut effectivement être appelé depuis un programme, zéro sinon.
Exemple (bien connu des utilisateurs de Dev-C++ ; pause est une commande MS-DOS/Windows) :
system("pause");
char *getenv(char *nom)Rend la chaine qui est la valeur de la variable d'environnement ayant le nom indiqué, ou NULL si une telle variable n'est pas définie. La notion de variable d'environnement est définie au niveau du système sous-jacent.
qsort
void qsort(void *tab, size t nbr, size t taille, int (*comp)(const void *, const void *))Quick sort, ou tri rapide. Cette fonction trie sur place (c'est-à-dire sans utiliser un tableaux auxiliaire), par ordre croissant, un tableau dont tab donne l'adresse de base, formé de nbr objets chacun ayant la taille indiquée.
Pour comparer les éléments du tableau, qsort utilise la fonction qui est la valeur de l'argument comp.
Cette fonction doit prendre les adresses de deux objets comme ceux dont le tableau est fait, et rendre une valeur négative, nulle ou positive selon que le premier objet est respectivement inférieur, égal ou supérieur au second.
Voir à la section 6.3.2, exemple 2, un modèle d'utilisation de cette fonction.
bsearch
int bsearch(const void *ptr, const void *tab, size t nbr, size t taille,
int (*comp)(const void *, const void *))Binary search, recherche dichotomique. Cette fonction recherche dans un tableau qui doit être trié, ayant l'adresse de base donnée par tab, formé de nbr objets chacun ayant la taille indiquée, un objet égal à celui ayant ptr pour adresse. Pour cela, elle utilise la fonction de comparaison donnée par comp, qui est définie comme pour qsort, voir ci-dessus.
abs
int abs(int x), long labs(long x)Valeur absolue, avec un argument int (resp. long) 73.
72La fonction time renvoie le nombre de secondes écoulées depuis le premier janvier 1970. Elle renvoie donc un nombre entier qui change toutes les secondes.
Si on doit écrire un programme devant initialiser plusieurs suites aléatoires distinctes en moins d'une seconde { ce qui est quand même rarissime { on aura un problème, qu'on peut régler en faisant intervenir d'autres fonctions de mesure du temps. Par exemple clock compte le temps (mais c'est un temps relatif au lancement du programme) en fractions de seconde, par exemple des millisecondes.
73La fonction correspondante pour les réels s'appelle fabs (cf. section VIII.D.5).
VIII-D-3. Traitement de chaines : string.h▲
strcpy
char *strcpy(char *destin, const char *source)Copie la chaine source à l'adresse destin. Rend destin.
strcat
char *strcat(char *destin, const char *source)Copie la chaine source à la suite de la chaine destin. Rend destin.
strcmp
int strcmp(const char *a, const char *b)Compare les chaines a et b pour l'ordre lexicographique (c'est-à-dire l'ordre par lequel on range les mots dans un dictionnaire) et rend une valeur négative, nulle ou positive selon que a est, respectivement, inférieur, égal ou supérieur à b.
strlen
size t strlen(const char *s)Rend le nombre de caractères de la chaine s. Il s'agit du nombre de caractères utiles : le caractère 'n0' qui se trouve à la fin de toutes les chaines n'est pas compté. Ainsi, strlen("ABC") vaut 3.
memcpy
void *memcpy(char *destin, const char *source, size t nombre)Copie la zone mémoire d'adresse source de de taille nombre dans la zone de même taille et d'adresse destin . Ces deux zones ne doivent pas se rencontrer.
memmove
void *memmove(char *destin, const char *source, size t nombre)Copie la zone mémoire d'adresse source de de taille nombre dans la zone de même taille et d'adresse destin . Fonctionne correctement même si ces deux zones se rencontrent ou se chevauchent.
VIII-D-4. Classification des caractères : ctype.h▲
Les éléments de cette bibliothèque peuvent être implantés soit par des fonctions, soit par des macros. Les prédicats rendent, lorsqu'ils sont vrais, une valeur non nulle qui n'est pas forcément égale à 1 :
- int islower(int c) , c est une lettre minuscule.
- int isupper(int c) , c est une lettre majuscule.
- int isalpha(int c) , c est une lettre.
- int isdigit(int c) , c est un chiffre décimal.
- int isalnum(int c) , c est une lettre ou un chiffre.
- int isspace(int c) , c est un caractère d'espacement : ' ', 'nt', 'nn', 'nr' ou 'nf'.
- int iscntrl(int c) , c est un caractère de contrôle (c'est-à-dire un caractère dont le code ASCII est compris entre 0 et 31).
- int isprint(int c) , c est un caractère imprimable, c'est-à-dire qu'il n'est pas un caractère de contrôle.
- int isgraph(int c) , c est un caractère imprimable autre qu'un caractère d'espacement.
- int ispunct(int c) , c est une ponctuation, c'est-à-dire un caractère imprimable qui n'est ni un caractère d'espacement, ni une lettre ni un chiffre.
- int tolower(int c), int toupper(int c) si c est une lettre majuscule (resp. minuscule) rend la lettre minuscule (resp. majuscule) correspondante, sinon rend le caractère c lui-même.
VIII-D-5. Fonctions mathématiques : math.h▲
- double sin(double x) rend la valeur de sin x
- double cos(double x) rend la valeur de cos x
- double tan(double x) rend la valeur de tan x
- double asin(double x) rend la valeur de arcsin x, dans [-π/2,π/2]. On doit avoir x ∈ [-1,1]
- double acos(double x) rend la valeur de arccos x, dans [0,π]. On doit avoir x ∈ [-1,1]
- double atan(double x) rend la valeur de arctan x, dans [-π/2,π/2]
- double atan2(double y, double x) rend la limite de la valeur de arctan v/u dans [-π/2,π/2] lorsque u → x+ et v → y. Pour x ≠ 0 c'est la même chose que arctan y/x
- double sinh(double x) rend la valeur du sinus hyperbolique de x, soit sh x = (ex-e-x)/2
- double cosh(double x) rend la valeur du cosinus hyperbolique de x, ch x = (ex+e-x)/2
- double tanh(double x) rend la valeur de la tangente hyperbolique de x, th x = chx/shx
- double exp(double x) rend la valeur de l'exponentielle de x, ex
- double log(double x) rend la valeur du logarithme népérien de x, log x. On doit avoir x > 0
- double log10(double x) rend la valeur du logarithme décimal de x, log10 x. On doit avoir x > 0
- double pow(double x, double y) rend la valeur de xy. Il se produit une erreur si x = 0 et y = 0 ou si x < 0 et y n'est pas entier
- double sqrt(double x) rend la valeur de √x. On doit avoir x ≥ 0
- double ceil(double x) rend la valeur du plus petit entier supérieur ou égal à x, transformé en double
- double floor(double x) rend la valeur du plus grand entier inférieur ou égal à x, transformé en double
- double fabs(double x) la valeur absolue de x
VIII-D-6. Limites propres à l'implémentation : limits.h, float.h▲
Ces fichiers en-tête définissent les tailles et les domaines de variation pour les types numériques.
Le fichier limits.h définit :
- CHAR_BIT nombre de bits par caractère.
- CHAR_MAX, CHAR_MIN valeurs extrêmes d'un char.
- SCHAR_MAX, SCHAR_MIN valeurs extrêmes d'un signed char.
- UCHAR_MAX valeur maximum d'un unsigned char.
- SHRT_MAX, SHRT_MIN valeurs extrêmes d'un short.
- USHRT_MAX valeur maximum d'un unsigned short.
- INT_MAX, INT_MIN valeurs extrêmes d'un int.
- UINT_MAX valeur maximum d'un unsigned int.
- LONG_MAX, LONG_MIN valeurs extrêmes d'un long.
- ULONG_MAX valeur maximum d'un unsigned long.
Le fichier float.h définit :
- FLT_DIG précision (nombre de chiffres décimaux de la mantisse).
- FLT_EPSILON plus petit nombre e tel que 1.0 + e ≠ 1.0
- FLT_MANT_DIG nombre de chiffres de la mantisse.
- FLT_MAX plus grand nombre représentable.
- FLT_MAX_10_EXP plus grand n tel que 10n soit représentable.
- FLT_MAX_EXP plus grand exposant n tel que FLT_RADIXn - 1 soit représentable.
- FLT_MIN plus petit nombre positif représentable (sous forme normalisée).
- FLT_MIN_10_EXP plus petit exposant n tel que 10n soit représentable (sous forme normalisée).
- FLT_MIN_EXP plus petit exposant n tel que FLT_RADIXn soit représentable (sous forme normalisée).
- FLT_RADIX base de la représentation exponentielle.
- FLT_ROUNDS type de l'arrondi pour l'addition.
Ces fichiers définissent également les constantes analogues pour les double (noms en « DBL_ ... » à la place de « FLT_ ... ») et les long double (noms en « LDBL_ ... »).